In vielen Software-Systemen und Software-Projekten besteht die Herausforderung, die Software einheitlich und gemäß der entschiedenen Architektur-Regeln zu entwickeln.
Auch neue Entwickler sollen die Architektur-Regeln einhalten oder sogar nach alten Architektur-Regeln arbeiten, falls das Projekt nur noch gewartet wird. Eine Dokumentation der Architektur-Regeln untersteht genauso wie Code-Kommentare der Software-Erosion und führt in der Regel zu mehr Verwirrung, als dass es eine Unterstützung ist. Mein Lieblings-Code-Kommentar ist folgender:
Deshalb habe ich nach Möglichkeiten gesucht, Architektur-Regeln in den Build-Prozess von Projekten zu integrieren. Eine der wichtigsten Regeln ist die Einhaltung der Architektur-Schichten, so dass z.B. keine Klasse der Rest-Controller-Schicht direkt mit der DB-Schicht interagiert, sondern die Service-Schicht verwenden muss. Ich habe mir folgende Lösungsansätze dafür genauer angesehen:
- Java-Modules bzw. verschiedene Java-Projekte zur Trennung von Schichten
- AspectJ und Code-Weaving für Methoden-Interceptoren
- Eigene Checkstyle-Erweiterung
- Eigener Annotation-Processor
- jQAssistant mit Neo4j
Mit Java-Modules können nur Architektur-Schichten festgelegt werden, und bei AspectJ ist es sehr komplex, Regeln zu definieren. Checkstyle und Annotation-Prozessoren können den Java-Code (Byte-Code, Source-Code) analysieren, aber es ist ein relativ aufwändiges Unterfangen und kann schwer parametrisiert werden.
Analyse mit jQAssistant
Schlussendlich bin ich zu dem Maven-Plugin jQAssistant gekommen, welches für meine Wünsche die passendste Lösung ist. jQAssistant wird im Maven-Build-Prozess gestartet und analysiert unter anderen folgende Projekt-Artefakte:
- Java Byte-Code mit Abhängigkeiten und Meta-Informationen
- Properties-Files, pom.xml
- Per Plugin können noch mehr Informationen aufgesammelt werden, wie beispielsweise Tabellen aus Excel-Dateien
Die Informationen werden in einer lokalen Neo4j Graphdatenbank gespeichert.
Um zu zeigen, was in die Datenbank aufgenommen wird, analysieren wir das Projekt Apache Commons Lang:
Apache Commons Lang für jQAssistant vorbereiten
Nach dem Import des Projekts reicht es, ein Maven-Plugin in den POM-File aufzunehmen.
Nach dem nächsten Build sind alle Informationen in der Datenbank aufgenommen. Mit dem Maven-Plugin kann auch ein Web-Server für Neo4j gestartet werden, der dann unter http://localhost:7474/ verfügbar ist.
Projekt-Übersicht mit jQAssistant
Unter den Klassen kann man z.B. nun nach allen “*Utils” Klassen suchen.
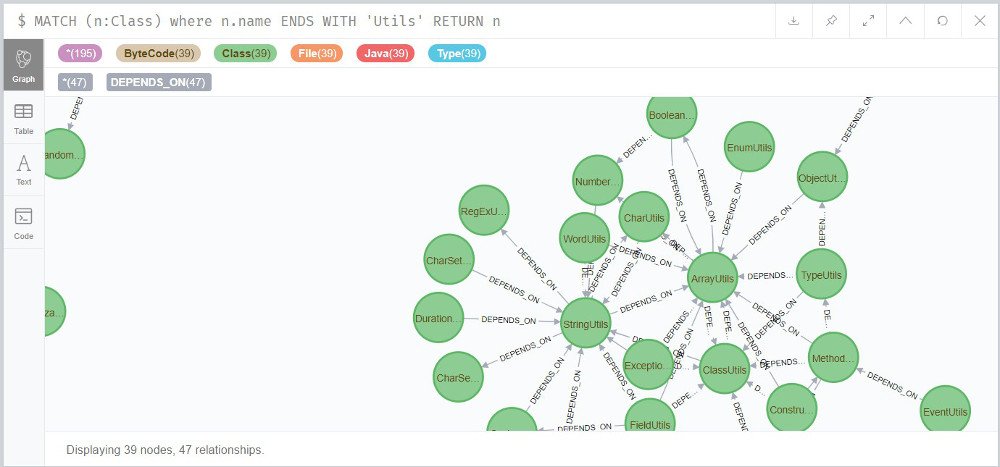
Die Suche “MATCH (n:Class) WHERE n.name ENDS WITH 'Utils' RETURN n” ist die spezielle DB-Abfragesprache Cypher, welche das Gegenstück zu SQL für Graphdatenbanken ist. Hier wird nach Knoten des Typs “Class” gesucht, deren Property “name” mit “Utils” endet. Die runden Klammern sollen den Knoten symbolisieren.
Hier kommt ein weiterer Vorteil von jQAssistant zum Vorschein. Es ist möglich, eine Code-Basis explorativ zu analysieren und daraufhin die Vermutungen per Cypher-Abfrage zu belegen.
In einem unbekannten Projekt interessiere ich mich als erstes für die komplexen, meist langen und unstrukturierten Methoden. Das kann näherungsweise mit dem zyklomatischen Index beschrieben werden.
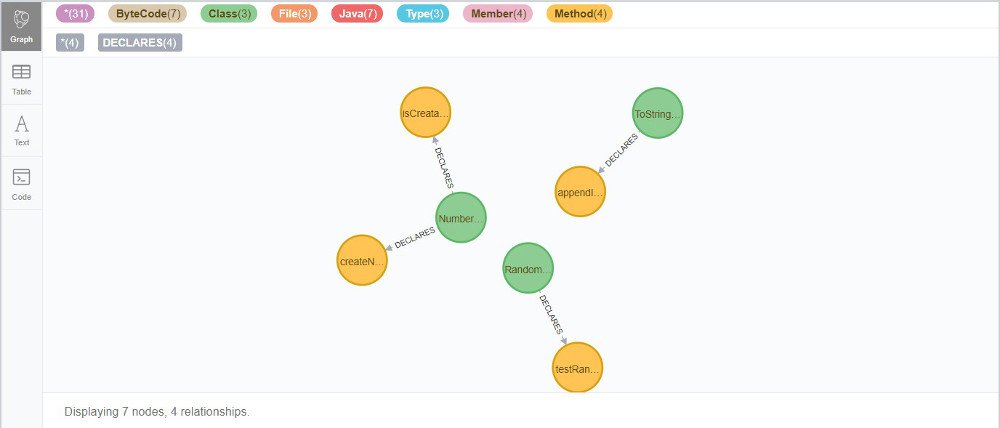
Hier sucht man nach Knoten-Verbindungen, die sich in ASCII-Art mit (…)-[…]->(…) also Knoten-Kante-Knoten beschreiben lässt.
Offenbar enthält die Klasse “NumberUtils” zwei relativ komplexe Methoden “boolean isCreatable(java.lang.String)” und “java.lang.Number createNumber(java.lang.String)”. Auch der “effectiveLineCount” wird berechnet und beide Methoden sind größer als 60 Zeilen.
Bei meinen weiteren Analysen habe ich bemerkt, dass sich relativ häufig toString-Methoden hintereinander aufrufen, und dies könnte zu Performance-Problemen führen. Hier eine erweiterte Abfrage.
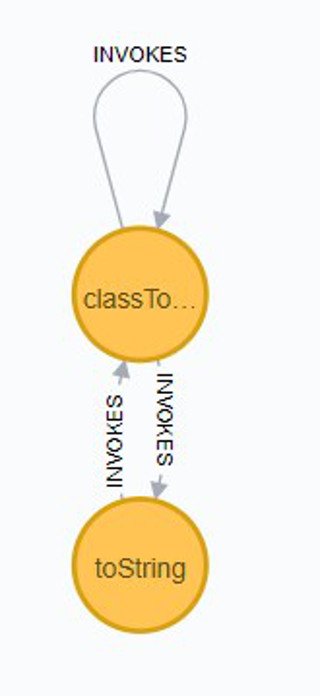
Interessanterweise wurde damit ein rekursiver Aufruf gefunden, den man sonst nicht sofort sehen würde.
“java.lang.String classToString(java.lang.Class)” ruft hier “java.lang.String toString(java.lang.reflect.Type)” auf, welche rekursiv wieder andere Klassen mit classToString aufrufen kann. Eine StringBuffer oder StringBuilder Variante könnte die Performance für diese Methoden erhöhen.
Zyklische Abhängigkeiten
Für das Auffinden von zyklischen Package-Strukturen ist die Cypher-Abfrage schon erheblich länger, aber dennoch relativ gut lesbar.
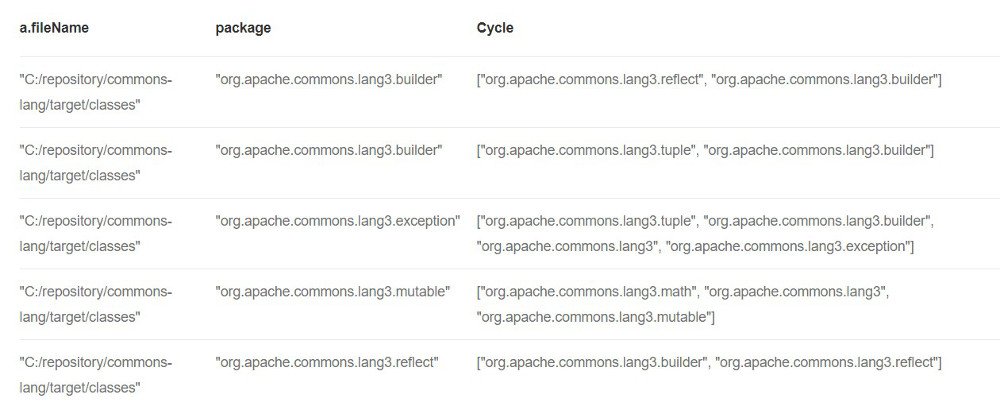
Dieser Select gibt nun keinen Graphen als Ergebnis zurück, sondern eine Tabelle.
Um Architektur-Regeln zu definieren, können diese nun mit Cypher beschrieben werden.
Ideen für weitere Software-Architektur-Regeln
Folgende Regeln sind zum Beispiel bei uns verwendet worden:
- Zu jeder <X>Entity Klasse in einem bestimmten Package gibt es eine dazugehörige <X> Klasse und eine <X>Mapping Klasse.
- Klassen aus dem Package “controller” dürfen nicht direkt die Klassen aus den Package “entity” verwenden.
- Utility Klassen dürfen keinen öffentlichen Konstruktor haben und haben keine Member-Variablen.
- Methoden in Enums und DTO-Klassen müssen einen niedrigen zyklomatischen Index haben.
- Wir unterscheiden zwischen Services, die “viel berechnen”, und Services, die “nichts berechnen und nur weiter delegieren”. ComputationServices dürfen keine anderen Services verwenden. DelegatingServices müssen in allen Methoden einen niedrigen zyklomatischen Index haben.
- In SpringBoot muss der DelegatingPasswordEncoder verwendet werden.
- Die Parameteranzahl von Methoden darf nicht zu groß werden.
- JPA-Repository-Interfaces sollen keine Default-Methoden enthalten.
- Reflection darf nur im Utility-Package verwendet werden.
- Controller-Methoden müssen mit dem Http-Verb beginnen.
Einbinung in JUnit
Um aus den Cypher-Abfragen Build-Constraints zu bekommen, wird im Projekt unter “jqassistant” für jedes Constraint eine XML-Datei abgelegt.
Mit jQAssistant kann man die Constraints auch gut parametrisieren. Das hilft, projektspezifische Anpassungen einfach zu definieren. Ein weiterer Vorteil ist, dass man Knoten per Cypher auch mit neuen Knoten-Typen annotieren kann. Damit werden Abfragen auf die neuen Knoten-Typen möglich und erleichtern die Lesbarkeit. Das folgende Beispiel zeigt beide Mechanismen.
Cypher im Detail
Um auch alle Architektur-Constraints definieren zu können, ist ein fundiertes Wissen über Cypher unausweichlich. Deshalb werden im Folgenden die wichtigsten Cypher-Details erklärt.
Oft ist es hilfreich, den Neo4j-Server ohne jQAssistant zum Testen von Abfragen zu starten. Damit kann man gezielte Szenarien und interessante Konstellationen für die Abfrage einfach erstellen.
Mit Docker ist der Neo4j-Server schnell erstellt.
Ohne das “volume”-Attribut werden alle Daten nach dem Stop des Containers gelöscht.
Knoten, Kanten und Attribute können einfach mit Cypher erstellt werden.
Die allgemeine Abfrage-Syntax lautet wie folgt:
“MATCH” ist die Selektion des Graphen, die nach “MATCH” als Graph-Template definiert wird. Es können auch mehrere Graph-Templates komma getrennt aufgeführt werden. “OPTIONAL MATCH” sind Graph-Templates, die vorkommen können, aber nicht müssen.
Der “WITH” Absatz ist ähnlich zu “RETURN”: es wird definiert, was für die darunterliegende Absätze verwendet wird. In der Regel werden die Ausdrücke mit “… AS <name>” für die Verwendung zu einer Variablen gebunden. Alle Variablen, die darunterliegend verwendet werden sollen, müssen in WITH angegeben werden.
“SKIP” und “LIMIT” sind die aus SQL bekannten Paging-Mechanismen.
MATCH
Im Graph-Template gibt es folgende Möglichkeiten:
- (n:Class): Knoten mit Label “Class” und wird mit der Variablen n referenziert.
- (n:Class {name: ‘Object’}): Knoten mit Label “Class” und Name-Attribut “Object”. Der Knoten wird mit der Variablen n referenziert.
- (k1)–(k2): Knoten k1 zu Knoten k2. Die Kanten-Richtung ist unerheblich.
- (k1)–>(k2): Knoten k1 zu Knoten k2. Die Kanten-Richtung wird beachtet.
- (k1)-[r]-(k2): Knoten k1 mit Kante r zu Knoten k2 (die Richtung ist unerheblich).
- (k1)-[r:CONTAINS]->(k2): Knoten k1 mit Kante r und Label “CONTAINS” zu Knoten k2.
- (k1)-[*1..3]->(k2): Knoten k1 mit 1..3 Kanten zu Knoten k2.
- (k1)-[*]->(k2): Knoten k1 mit beliebigen Kanten zu Knoten k2.
- shortestPath((c1:Class)-[*..6]-(c2:Class)): Kürzeste Pfade bis zu 6 Kanten von Class c1 zu Class c2.
- allShortestPaths((c1:Class)-[*..6]->(c2:Class)): Alle kürzesten Pfade bis zu 6 Kanten von Class c1 zu Class c2.
- p = (k1)–>(k2): Knoten k1 zu Knoten k2. Die Kanten-Richtung wird beachtet. Der Pfad wird der Variablen p zugewiesen.
- NOT (k1)-[r:CONTAINS]->(k2): Keine Verbindungen mit Knoten k1 über Kante r und Label “CONTAINS” zu Knoten k2 sind zugelassen.
RETURN / WITH
Hauptsächlich in RETURN und WITH werden die Aggregations-Funktionen verwendet:
- count(*): Aggregations-Funktion, die alle Reihen zählt.
- count(n): Aggregations-Funktion, die alle nicht leeren Elemente zählt.
- sum(n.x), avg(n.x), min(n.x), max(n.x): Aggregations-Funktion für numerische Werte.
- collect(n): Aggregiert alle Knoten des Matches zu einer Liste.
WHERE
Folgende Operatoren werden unterstützt (die Liste ist nicht vollständig):
- n.name: Attribut “name” des Knoten n wählen.
- n[‘name’ + x]: Dynamische Attributabfrage (‘name’+x) für den Knoten n.
- n.x + n.y, n.x – n.y , n.x * n.y , n.x / n.y , n.x % n.y , n.x ^ n.y: Mathematische Operatoren von Attributen.
- n.x = n.y , n.x <> n.y , n.x < n.y , n.x > n.y , n.x <= n.y , n.x >= n.y , n.x IS NULL, n.x IS NOT NULL: Vergleichsoperatoren von Attributen.
- n.x STARTS WITH ‘search’, n.x ENDS WITH ‘search’, n.x CONTAINS ‘search’: String-Vergleich von Attributen.
- AND, OR, NOT: Boolsche Operatoren. In der Regel werden diese für die Verknüpfung von Termen genutzt.
- n.x + n.y, n.x =~ ‘regex’: Konkatenation von Strings und Regex-Matcher.
Des Weiteren gibt es auch Listen-Operatoren:
- [‚a‘, ‚b‘, ‚c‘]: Explizit definierte Liste.
- range(<start>, <end>, <step>): Erzeugt eine Zahlen-Liste. Step ist dabei optional.
- labels(n): Liste von Labels des Konten n.
- nodes(p): Liste von Knoten eines Pfads.
- relationships(p): Liste von Kanten eines Pfads.
- keys(n): Liste alle Attribut-Keys eines Pfads.
- UNWIND <list> AS item MATCH (n {name: item}): Die Liste wird in einzelne Zeilen der Suche transformiert und kann weiter verwendet werden, wie z.B. mit MATCH.
- [(a)–>(b) WHERE b.name = ‚Object‘ | b.fqn]: Pattern comprehension, um eine Liste zu erzeugen.
- <list>[0]: Listen-Zugriff auf den Index 0.
- size(<list>): Größe der Liste.
- reverse(<list>): Liste umkehren.
- head(<list>), last(<list>), tail(<list>): Erstes Element, letztes Element und alles außer dem ersten Element als Liste.
- [item IN <list> WHERE <condition> | item.name]: Mapping und Filterung einer Liste. WHERE <condition> ist optional.
- reduce(s = <start>, x IN <list> | f(s,x)): Reduce-Operation der Liste mit vorgegebenen Start und f als Reduce-Funktion.
- list1 + list2: Konkatenation von Listen.
- n.x in <list>: Abfrage, ob das Attribut x des Knoten n in der Liste enthalten ist.
Auch sind Allquantoren mittels Listen-Prädikate möglich:
- all(item IN <list> WHERE f(item)): Gibt true zurück, wenn in allen Elementen der Liste die Prädikatsfunktion true wird.
- any(item IN <list> WHERE f(item)): Gibt true zurück, wenn in mindestens einem Element der Liste die Prädikatsfunktion true wird.
- none(item IN <list> WHERE f(item)): Gibt true zurück, wenn in keinem Element der Liste die Prädikatsfunktion true wird.
- single(item IN <list> WHERE f(item)): Gibt true zurück, wenn in genau einem Element der Liste die Prädikatsfunktion true wird.
Abschließendes Beispiel: Selektiere alle Klassen, die in einen bestimmten Package liegen und zu der es keine entsprechende “Data” Klasse gibt.
- Selektiere alle Knoten mit Klassen-Label.
- Filter Klassen, die nicht mit “com.wogra” beginnen, heraus.
- Aggregiere alle Knoten zu einer Liste.
- Starte mit einer neuen Suche und selektiere alle Knoten mit Klassen-Label. Binde die Knoten an die Referenz c1.
- Behalte c1, falls es keine Klasse c2 gibt, die den gleichen Namen wie c1 und dazu “Data” hat und…
- Mit “com.wogra” startet, mit “Data” endet und kein “$” enthält (keine anonyme oder innere Klasse).
- Gebe c1 zurück.
Fazit
jQAssistant bietet eine gute Möglichkeit, Software-Architektur-Regeln flexibel zu definieren. Es stehen viele Plugins zur Verfügung. Auch die Anbindung von neuen Projekt-Artefakten für die Graphen-Datenbank ist mit geringem Aufwand möglich. Lediglich die Syntax und Semantik von Cypher muss selbst für einfache Abfragen beherrscht werden.
jQAssistant kann aber auch für Neo4j-Interessenten nützlich sein — hat man doch damit sehr schnell einen komplexen fachgetriebenen Graphen aufgebaut, womit man seine Abfrage-Künste ausprobieren kann.

Aufgrund seiner hohen Ansprüche an Softwarequalität und seinem Fachwissen über langlebige Softwarearchitekturen ist er bei der WOGRA seit 2016 der Hauptverantwortliche für die technische Umsetzung von Softwareentwicklungsprojekten (Chief Software Architect).
