Heute wird in allen Bereichen mit Docker gearbeitet. Docker-Container lassen sich wahnsinnig schnell und einfach bereitstellen, aber was, wenn mal nicht alles glatt läuft?
Da das Einrichten von Docker im Projekt meist schnell durchgeführt ist, muss nur sehr selten nachträglich konfiguriert werden. Das führt jedoch auch dazu, dass das Docker-Wissen im Team meistens schlecht verteilt ist. Deshalb kann es passieren, dass die Fehlerbehandlung bei jemandem landet, der wenig, bis keine Erfahrung in diesem Bereich hat.
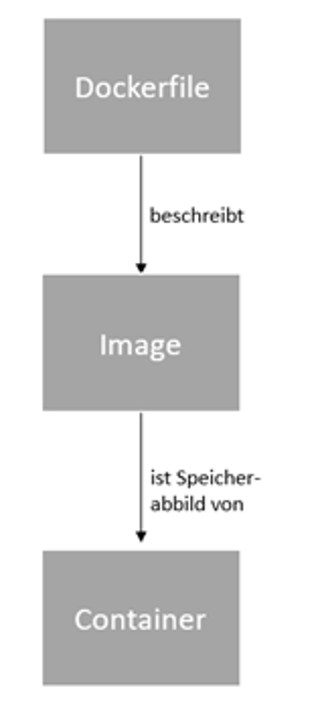
Es ist nicht nötig, sich tiefgehendes Wissen rund um Docker anzueignen, um zu debuggen. Aber um die verschiedenen Möglichkeiten, Fehler zu analysieren zu verstehen und sie zu beheben, sollte ein Verständnis für die Begriffe Dockerfile, Docker-Image und -Container vorhanden sein.
Das Dockerfile ist ein Bauplan zur Erstellung eines Docker-Images. Diese Datei liegt im Projekt der Anwendung und beschreibt Schritt für Schritt, wie die Anwendung aufgebaut und gestartet wird.
Das Docker-Image ist wiederum ein Template, aus dem beliebig viele Docker-Container gebaut werden können. Das fertig erstellte Image kann nicht mehr bearbeitet, sondern nur komplett neu gebaut werden.
Der Docker-Container benutzt das Image, um eine Laufzeitumgebung zu starten. Dateien innerhalb des Containers sind konfigurierbar und weitere Befehle können ausgeführt werden. Wenn der Container neu gestartet wird, sind alle Änderungen, die zur Fehlerbehandlung durchgeführt wurden, verloren.
Damit ein Problem also dauerhaft gelöst werden kann, muss dies bereits vor dem Build-Prozess geschehen. Das bedeutet, dass die Lösung entweder Teil des Applikation-Codes sein oder als expliziter Schritt im Dockerfile eingefügt werden muss.

Finden Sie jetzt Ihre Wunsch-Domain.
-
Große Auswahl an günstigen Domain-Endungen.
Keine verdeckte Kosten.
Praxisbeispiel: Bcrypt Invalid ELF header
Um verschiedene Lösungsansätze an einem praxisnahen Beispiel aufzuzeigen, wird unter Windows eine Node.js-App erstellt. Diese besitzt eine kleine SQLite-Datenbank, in der sie Benutzeraccounts und die zugehörigen Passwörter speichert. Um die Passwörter sicher zu verwahren, werden sie nicht verschlüsselt, sondern gehashed. Das bedeutet, dass der ursprüngliche Text nach der Umwandlung nicht mehr zurückverwandelt werden kann. Es kann also nur geprüft werden, ob derselbe Text unter denselben Umständen wieder denselben abstrakten String ergibt. Für das Hashen der Passwörter wird die bcrypt-Bibliothek verwendet. Um die Sicherheit weiter zu erhöhen, wird mit Hilfe des Moduls auch ein entsprechendes Salt erstellt. Hierbei handelt es sich um eine zufällig generierte Zeichenfolge, die an das Passwort gehängt wird, bevor der Hashing-Algorithmus ausgeführt wird.
Als nächstes soll diese Applikation zu einem Docker-Image verpackt werden. Dafür muss zunächst der Bauplan, also das Dockerfile, geschrieben werden.
Als erster Schritt wird ein Node-Image als Basis herangezogen. Das gängige Verzeichnis, in dem die Anwendung innerhalb des Docker-Containers laufen wird, ist /user/src/app. In diesen Pfad wird die package.json und die package-lock.json des Node-Projektes kopiert. In dieser Datei werden die externen Module definiert, die von der Anwendung benötigt werden. In dem Verzeichnis wird dann der Installierprozess gestartet: im Falle der Node.js-Applikation also ein npm install. Es empfiehlt sich jedoch, npm ci zu verwenden, damit exakt die gleichen Versionen installiert werden, die in der lock-Datei angegeben wurden. Danach werden die eigentlichen Applikationsdateien ebenfalls in das Verzeichnis kopiert, ein Port festgelegt und der Startbefehl der Anwendung verknüpft.
In diesem Fall ist für die Applikation mit „npm start“ der Befehl „node app.js“ hinterlegt. Das bedeutet, dass die Einstiegsdatei app.js als Node-Anwendung gestartet wird.
Wenn das Dockerfile fertig erstellt ist, kann es als Schritt-Für-Schritt-Anleitung benutzt werden, um ein entsprechendes Image zu bauen.
Der Build-Prozess des Docker-Images wird mit diesem Befehl gestartet:
Mit Hilfe eines Tags (-t) kann ein Referenzname angegeben werden, in diesem Fall debugging-demo, unter dem das Image leichter wiedergefunden und gestartet werden kann. Wird nichts angegeben, erhält das Image als Referenz eine zufällig generierte Id.
Mit dem Befehl docker image ls kann über die Konsole eine Liste aller erstellten Images ausgegeben werden.

Das Image kann nun als Container unter dem Port 8091 gestartet werden:
Wurde kein Referenzname angegeben, muss das debugging-demo durch eine entsprechende Image-Id ersetzt werden.
Nach dem Ausführen des Startbefehls „node app.js“ kommt es jedoch zu einem Fehler, der in der Konsole ausgegeben wird.
Die bycrpt-Bibliothek, die zum Absichern der Passwörter unerlässlich ist, kann innerhalb des Docker-Containers nicht verwendet werden.
Docker-Container manipulieren
Wenn ein Fehler beim Starten des Docker-Containers auftritt, sollte der erste Schritt immer sein zu überprüfen, ob der Startbefehl auf der verpackten Codebasis normal ausführbar ist. In diesem Fall funktioniert das Starten der Applikation unter Windows fehlerfrei, und es gibt keinen bcrypt-Fehler.
Eine schnelle Recherche liefert eine Erklärung für das Problem: Bei der bcrypt-Bibliothek kann es zu Fehlern kommen, wenn die Installation zwischen Betriebssystemen ausgetauscht wird. In diesem Fall wurde die ursprüngliche Installation für Windows ausgeführt und verursacht Probleme in dem auf Linux basierenden Docker-Container.
Um diese Theorie zu überprüfen kann der Docker-Container nun mit Konsolenzugriff gestartet werden:
Die Konsole startet im definierten Quellordner der Applikation /usr/src/app. Wird dort nun mit dem ls-Befehl der Inhalt des Verzeichnisses angezeigt, werden, wie im Dockerfile definiert, alle kopierten Elemente der Node-Anwendungen angezeigt. Unter anderem auch das node_modules Verzeichnis, in dem sich die potenziell fehlerhafte Installation des bcrypt-Moduls befinden sollte.
Mit dem Verzeichniswechsel-Befehl (cd – change directory) kann nun in den Ordner navigiert werden. Dafür wird in der Konsole cd node_modules/ ausgeführt. Nach einer kurzen Überprüfung des Inhaltes im Verzeichnis, durch ein erneutes Ausführen des ls-Befehles, kann das betroffene Paket gefunden werden. In diesem Fall wurde ein bcrypt und ein bcrypt-pbkdf Verzeichnis erstellt.
Diese Verzeichnisse können mit Remove-Befehl (rm) direkt im Docker-Container entfernt werden. Mit rm -r bcrypt und rm -r bcrypt-pbkdf/ werden nun die beiden betroffenen Ordner entfernt.
Danach wird mit „cd ..“ zurück in das übergeordnete Verzeichnis navigiert. Hierbei handelt es sich wieder um den Startpunkt unserer Applikation /usr/src/app, von dem aus die definierten Befehle unserer Anwendung ausgeführt werden können.
Mit npm install können nun die beiden gelöschten bcrypt-Pakete nachinstalliert werden. Danach kann im selben Ordner mit npm start die Anwendung erneut ausgeführt werden.
Build-Fehler beseitigen
Die händische Manipulation des Docker-Containers ist keine langfristige Lösung. In diesem Fall hat sie jedoch geholfen, die Theorie zu bestätigen, dass eine bcrypt-Installation für das falsche Betriebssystem bereitgestellt wurde. Es wäre eine Möglichkeit, diese Schritte nach dem Kopier-Schritt in das Dockerfile aufzunehmen. Das eigentliche Problem, dass die Windows-Installation des bcrypt-Moduls nicht in dem Docker-Image hätte landen dürfen, besteht mit dieser Lösung nach wie vor.
Eine weitere Möglichkeit ist es, die Windows-Installation nachträglich für Linux umzubauen. Hierfür kann das node-pre-gyp-Modul verwendet werden. Auch diese Lösung flickt nur den eigentlichen Fehler und löst ihn nicht. Obwohl diese Lösung nicht die erstrebenswerteste für genau dieses Problem ist, heißt das nicht, dass es sich nicht lohnt, das Modul kennengelernt zu haben.
Besonders wenn mit JavaScript für verschiedene Betriebssysteme kompiliert wird, z.B. als Desktop-Anwendung, wird man schnell um das node-pre-gyp-Modul nicht mehr herumkommen. Es ermöglicht, die Abhängigkeiten einer Applikation für verschiedene Plattformen erneut zu kompilieren. Das betrifft nicht nur Betriebssystem-Abweichungen, sondern eignet sich auch für Fälle, an denen z.B. unterschiedliche Node-Versionen in den verschiedenen Bibliotheken angezogen werden.
In diesem Fall würde man node-pre-gyp global installieren, sobald das Kopieren abgeschlossen ist. Danach kann der rebuild-Befehl aus dem Modul genutzt werden, um die bcrypt-Installation für den auf Linux laufenden Container erneut zu bauen.
Durch den „Rebuild“ des Moduls für das jeweilige Betriebssystem tritt der Fehler nicht mehr auf, und der Container kann nun problemlos gestartet werden. Dieser Lösungsansatz ist zwar leichter verständlich als die Navigation durch Verzeichnisse und dem gezielten Löschen scheinbar wahlloser Verzeichnisse, jedoch wird hier noch eine zusätzliche Abhängigkeit dazu geholt, die nicht zwingend erforderlich ist. Zusätzlich fängt der Build-Ablauf an, von dem Standard in der lokalen Entwicklungsumgebung abzuweichen.
Das eigentliche Problem, dass die für Windows installierten node_modules aus dem Applikationsverzeichnis in den Linux-Kontext kopiert wurden, wurde hiermit auch nicht behandelt.
Die beste Lösung ist es also, eine entsprechende .dockerignore-Datei zu erstellen. Diese sollte sich auf derselben Ebene wie das eigentliche Dockerfile befinden und nur die Verzeichnisnamen enthalten, die exkludiert werden sollen. In diesem Fall also mindestens der node_modules-Ordner.
Befinden sich die Build-Dateien in einem dedizierten Verzeichnis, muss das bei der Angabe entsprechend beachtet werden.
Für das Ausschließen von Dateien und Verzeichnissen in der .dockerignore-Datei gibt es verschiedene Möglichkeiten. Eine komplette Liste mit Syntax befindet sich hier.
Wird eine entsprechende .dockerignore-Datei neben das Dockerfile gelegt und ein Image gebaut, tritt der Fehler nicht mehr auf. Ganz ohne, dass zusätzliche Zeit für einen extra Kompilierschritt oder sogar ein neues Modul hinzugefügt wurde.
Wie an diesem Beispiel gut ersichtlich ist, sollte bei der Fehlerbehebung im Allgemeinen immer hinterfragt werden, ob die eigentlichen Probleme oder nur deren Symptome behoben werden.
Container über die Konsole debuggen
Abschließend sollte nicht unerwähnt bleiben, dass es durchaus von Vorteil sein kann, die Docker-Befehle nur über das Terminal auszuführen. Visuelle Oberflächen wie z.B. Docker Desktop ermöglichen das schnelle Aufrufen der Übersicht aller Images und das Starten eines Containers mit einem Klick, haben jedoch auch ihre Nachteile.
Wenn z.B. ein Container bereits beim Starten abstürzt und direkt wieder beendet wird, ist es über die grafische Oberfläche nicht möglich, Zugriff auf die Konsole zu erhalten.
Soll der Inhalt des Containers genauer untersucht werden, kann dieser über das Terminal mit diesem Befehl gestartet werden:
Hierbei wird der Startbefehl, in unserem Fall npm start, nicht ausgeführt. Wird dieser Befehl nun manuell angestoßen, bleibt der Konsolenzugriff auch nach dem Absturz erhalten. Dadurch ist es möglich, zu den frisch gefüllten Logs des Containers zu navigieren.
Da in dem Beispiel-Ordner mit npm gearbeitet wird, muss zunächst in den entsprechenden Ordner navigiert werden. Das Einstiegsverzeichnis in der Konsole ist wie immer der Ordner, in dem die Applikation liegt. Deshalb muss zunächst weiter in die Überverzeichnisse navigiert werden, bis in der Liste des Verzeichnisinhaltes (Anzeigebefehl in der Konsole: ls) der root-Ordner aufgezählt wird. Von dort kann in den Unterordner root/.npm/_logs navigiert werden.
Eine Anzeige des Ordner Inhaltes liefert den Logeintrag 2021-07-01T05_16_12_309Z-debug.log
Der Dateiverkettungs-Befehl cat (von concatenate) kann dazu genutzt werden, in der Konsole Dateiinhalte vollständig anzuzeigen.
Diese Logausgabe wäre mit dem abgestürzten Docker-Container in Docker Desktop nicht möglich.
Docker Debugging – Zusammenfassung
Um Fehler in einem Docker-Container zu beheben, muss das Image, aus dem der Container gestartet wird, die Ursache bereinigen. Das bedeutet, dass der Fehler entweder direkt im eigentlichen Code der Anwendung ausgebessert werden muss oder spätestens im Dockerfile, der als Bauplan für das Image dient. Wird ein Fehler zum Beispiel händisch im Container behoben, wird diese Lösung bei einem Neustart nicht angewendet, und der Fehler tritt erneut auf. Die Analyse des Fehlers innerhalb des Containers oder auch das Auslesen der detaillierten Logfiles über die Konsole kann jedoch durchaus von Vorteil sein.
Wie bei Software-Fehlern, gibt es auch bei Docker-Problemen meistens verschiedene Herangehensweisen, wie das Problem behoben werden kann. Hierbei sollte jedoch immer beachtet werden, dass die Ursache des Problems aus der Welt geschafft wird und nicht nur die Symptome behoben werden. Stehen mehrere Möglichkeiten zur Auswahl, sollte analysiert werden, ob sich die Performanz des Build-Prozesses oder die Sicherheit durch den Lösungsansatz verschlechtert.
Alles in allem gibt es für die Analyse von Fehlern in Docker-Containern einige Hilfsmittel und Methoden, die viele Informationen liefern, anhand derer Lösungsvorschläge recherchiert oder direkt selbst ausprobiert werden können.
Happy Docker Debugging!
Hier finden Sie weitere Artikel zum Thema:
- Interaktive Arbeit mit Docker – Eine Einführung in den Betrieb von Docker-Containern Teil 1
- Containerdaten und Backups für Docker – Eine Einführung in den Betrieb von Docker-Containern Teil 2
- Eigene Docker-Images bauen – Einführung in den Betrieb von Docker-Containern – Teil 3
- Grundlagen der Orchestrierung – Eine Einführung in den Betrieb von Docker-Containern Teil 4
- Docker im Entwickleralltag

- Einführung in Elasticsearch – Teil 2: Schneller suchen, schneller finden – performante Suche mit Elasticsearch - 4. Februar 2025
- Eine Einführung in Elasticsearch – Teil 1: Was ist Elasticsearch und wie richtet man die Suchmaschine ein? - 20. Januar 2025
- Selbstorganisation im IT-Alltag mit Notion - 18. Oktober 2023
