In den 90er Jahren arbeitete ich bei einem Softwareunternehmen, das viele unterschiedliche Programme für große und kleine Kunden entwickelte. Wir waren recht offen in Hinsicht auf die Entwicklungsmethoden – vielleicht auch, weil wir recht neu am Markt waren und uns noch nicht auf einen bestimmten Weg festgelegt hatten. Allerdings sahen wir diese Offenheit auch als Tugend, denn wir wollten gerne für die Kunden jeweils die besten Lösungen finden. Da gab es Software, die in C++, Delphi und VBA geschrieben wurde, verschiedene Datenbanken, Umgebungen wie Business Objects Data Warehousing oder Lotus Notes als Unternehmensplattform. Auch im Detail waren die Anforderungen natürlich immer unterschiedlich – zwei Delphi-Kunden wurden vermutlich mit verschiedenen Versionen von Delphi bedient, wie auch mit unterschiedlichen Versionen von Dritthersteller-Komponenten und anderem mehr.
So ergab sich für die Firma das Problem, dass Entwickler effizient von einer Kundenumgebung in die andere wechseln mussten. Natürlich wurde an einem Projekt oft eine ganze Zeit lang geradlinig gearbeitet. Aber dann kam der Zeitpunkt, an dem sich die Software der Fertigstellung näherte, Entwickler neu auf andere Projekte verteilt wurden, und letztlich die Software vielleicht nur zur Fehlerbehebung noch einmal angefasst wurde. Für die Arbeit am Projekt brauchte ein Entwickler aber Visual Studio Version 1.5, eine bestimmte Oracle-Version, Crystal Reports Version X, Installshield Version X usw. Für ein anderes Projekt brauchte er Delphi, Interbase, mehrere Komponenten-Libraries und ganz andere Versionen von Crystal Reports und Installshield. Offensichtlich war der Wechsel zwischen der einen und der anderen Entwicklungsumgebung nicht einfach, so dass die Reaktion auf Kundenanfragen mit Bezug auf ein „altes“ Projekt sehr zeitaufwändig wurde.
Virtuelle Maschinen waren eine Wunderlösung für Entwickler
Die Lösung für all diese Probleme fand sich letztlich im Jahre 1999, mit dem Release von VMWare. Endlich konnten wir kunden- und projektspezifische Entwicklungsumgebungen in virtuellen Maschinen kapseln, archivieren und wiederherstellen. Natürlich war die Arbeit innerhalb, und mit, den virtuellen Umgebungen nicht unbedingt ein Genuss. Eine Umgebung mit Windows 98 oder Windows NT erforderte mehrere Gigabytes an Speicher, und das Kopieren und Sichern einer solchen VM war zeitaufwändig. Die Leistung der virtuellen Umgebungen war ebenfalls deutlich reduziert, so dass etwa der Umgang mit einer IDE nicht immer erfreulich war.
Wir verwendeten zu der Zeit Windows 98 als Arbeitsplatzsysteme, da Windows NT 4 sehr schlecht mit mehreren Bildschirmen am PC umgehen konnte. Nun stellte sich allerdings heraus, dass sich Windows 98 als Host für VMWare nicht besonders gut eignete, und wir stiegen daher auf Linux als Basissystem um, da hier sowohl die Unterstützung von mehreren Bildschirmen als auch die Leistungsfähigkeit des Host-Systems unproblematisch war. Ich erinnere mich noch heute an ein Projekt, zu dessen Entwicklung ich zwei unterschiedliche Windows-Systeme parallel in virtuellen Maschinen auf dem Linux-Host laufen ließ – das war die beeindruckendste Technologie, die wir uns damals vorstellen konnten.
Eine virtuelle Maschine mit einer archivierten Entwicklungsumgebung aus dem Jahr 2000: Windows NT4 und Borland Delphi 5
Natürlich hat sich seit diesen Tagen viel getan für Entwickler, IT-Administratoren und DevOps, aber die Bedeutung von Virtualisierungstechnologie in der heutigen Welt ist sicherlich nicht kleiner als zum Jahrtausendwechsel. Fachlich unterscheiden wir nun zwischen unterschiedlichen Graden der Virtualisierung, und die Einheit, die abgesehen von der virtuellen Maschine selbst den größten Stellenwert hat, ist der Container. Virtuelle Maschinen werden direkt von einem Hypervisor überwacht, bzw. von diesem „koordiniert“, um Konflikte aller Art zu vermeiden und eine ordnungsgemäße Trennung einer VM von einer anderen zu erreichen. Container hingegen teilen sich manche Ressourcen des Hosts. Zum Beispiel können Sie bei mehreren laufenden Docker-Containern auf einem Linux-Host die Prozesse aller Container nebeneinander laufen sehen. So können Container innerhalb von virtuellen Maschinen laufen – beispielsweise unterstützen die Virtual Server-Produkte von Host Europe auch den Betrieb von Docker, so dass mehrere Container in einem Virtual Server betrieben werden können.
Die Idee, Ausführungskontexte strikt voneinander zu trennen, zum Beispiel aus Sicherheitsgründen, gab es schon lange vor der Verfügbarkeit von VMWare (wenn auch nicht vor der Erfindung des Hypervisors selbst, den gab es schon Ende der 1960er bei IBM). In Unix-Systemen verbreitete sich seit etwa 1979 der Systemaufruf „chroot„, mit dem der Zugriff eines laufenden Prozesses auf einen bestimmten Teil des Dateisystems beschränkt werden konnte. Daraus entwickelten sich das „jail“ in FreeBSD sowie verschiedene andere ähnliche Systeme, bis 2008 die Linux Containers (LXC) entstanden. Diese Technologie ist heute noch in Verwendung und auch deshalb bedeutsam, weil Docker auf ihrer Basis entwickelt wurde.
Docker ist im Deployment nicht mehr wegzudenken
Genug zur Vorgeschichte. Heute kennen Entwickler wie IT-Leute natürlich Docker und Container im Allgemeinen, wenn sie sich noch nicht zu Fachleuten in der Orchestrierung, dem Deployment und der Skalierung entwickelt haben (dank Tools wie docker-compose, Kubernetes, Vagrant, Puppet, Chef, Terraform und anderen). Selbst in lokalen Deployments weiss man die Flexibilität von Container-basierten Strukturen zu schätzen, und eine moderne Cloud-Umgebung ist ohne Virtualisierung gar nicht vorstellbar. Um virtuelle Systeme in einer Cloud effizient zu nutzen und die Skalierbarkeit einzelner Komponenten eines Anwendungssystems in der Cloud zu gewährleisten, dienen Container als kurzlebige Kapselungseinheiten. Sie stellen gemeinsam mit „Infrastructure as Code“ einen Stützpfeiler der DevOps-Idee dar.
Nun habe ich selbst in Kundengesprächen und Konferenzvorträgen die Erfahrung gemacht, dass eine grosse Lücke zwischen solchen Entwicklern klafft, die sich mit den angesprochenen Technologien und Produkten hervorragend auskennen, und jenen, die damit im Alltag nichts zu tun haben und daher Container nur theoretisch kennen. Das soll keine Kritik sein, denn die spezifischen Details, die ich angesprochen habe, sind für die Arbeit gewisser Gruppen von Entwicklern tatsächlich völlig irrelevant. Allerdings gibt es andere Aspekte der Containertechnologie, die ich als Entwickler im Alltag sehr zu schätzen weiss. Wie die Virtualisierungstechnologie vor 20 Jahren haben es Container heute geschafft, sich einen grossen Stellenwert in meinem Werkzeugkasten zu erarbeiten. Ich möchte Docker nicht mehr missen! Vielleicht verwende ich demnächst ein anderes Tool als Docker – solange die Idee dieselbe bleibt.
Zunächst ist es beeindruckend, wie einfach der Einsatz von Docker ad-hoc, also direkt an der Kommandozeile ist. Vielleicht sind Sie ein Entwickler, der lieber klickt als tippt? Auch dann ist Docker mit seiner grafischen Desktop-Oberfläche einfach zu bedienen. Ich tippe allerdings lieber, und ich mag auch die Tatsache, dass meine Kenntnisse der wichtigen Kommandos auf diese Weise besser auf andere Systeme übertragbar sind.
Gerade in den letzten Tagen habe ich zum Beispiel etwas Wartungsarbeit an einer Software getan, die Abfragen in MongoDB durchführt. Früher einmal hätte ich zu diesem Zweck zunächst MongoDB installieren oder mich vergewissern müssen, dass ich eine aktuelle Version habe. Hätte ich bereits eine Version auf dem Computer gefunden, müsste ich diese als nächstes aufräumen, um sicherzustellen, dass keine alten Testdaten den aktuellen Einsatzfall verfälschen könnten. Speziell für MongoDB ist dies nicht so gewöhnlich, aber etwa für MySQL oder MariaDB wäre auch die Frage zu klären, ob eine Version auf meinem Computer nicht von einer Anwendungssoftware bereits verwendet wird. Irgendwann käme ich dann dazu, für die Entwicklungsarbeit die nötigen Testdaten zu importieren und mich dem eigentlichen Problem zu widmen. Zwischendurch müsste ich diese Schritte vermutlich mehrmals wiederholen, um etwa verschieden Testdatensätze zu laden oder den Ausgangszustand wiederherzustellen.
Ad-Hoc Serverdienste mit Docker
Alles das ist mit Docker nicht nötig. Erstens können Sie mit einem einzigen Kommando eine beliebige Version von MongoDB (oder praktisch jeder anderen Serversoftware) herunterladen:
Natürlich funktioniert dies auf „allen“ Plattformen, also jedenfalls unter Linux, Windows und Mac OS. Für Windows gibt es von MongoDB auch Varianten, die im Container mit Windows Server Core arbeiten – auf solche Details möchte ich hier allerdings nicht näher eingehen, da sie uns wiederum in den Bereich von Deployments bringen. Für meine Bedürfnisse als Entwickler sind solche Unterscheidungen gewöhnlich nicht wichtig.
Sie müssen übrigens auch gar nicht unbedingt das Image zuerst explizit herunterladen. Wenn Sie einfach einen Container auf Basis eines Images starten, das bisher noch nicht lokal vorliegt, wird es automatisch heruntergeladen. Sie könnten Ihre Arbeit mit MongoDB also direkt so beginnen:
Dieses Beispiel enthält drei Optionen die ich oft verwende. –rm bedeutet, dass der Container nach dem Lauf komplett wieder entfernt wird. Ohne die Option bleibt der Container bestehen und verwendet beim nächsten Start eventuell gewisse Zustandsinformationen weiter. –name gibt dem laufenden Container einen lesbaren Namen, so dass Sie einfach darauf zugreifen können. Mit -p schliesslich wird ein Netzwerkport aus dem laufenden Container auf den Host abgebildet. Dies ist sowohl wichtig als auch praktisch – der Effekt ist derselbe, als würde MongoDB direkt auf dem Host laufen, so dass Anwendungssoftware unmittelbar und ohne besondere Konfiguration darauf zugreifen kann. Andererseits können Sie aber auch einen anderen lokalen Port mit dem Standardport im Container verbinden, so dass mehrere MongoDB-Instanzen gleichzeitig laufen können. Kein Problem also, wenn es lokal bereits eine geben sollte!
Wenn Sie direkt mit dem laufenden Container arbeiten möchten, können Sie dort auch Kommandos ausführen. Ich verwende diese Methode etwa, um mit der mongo Shell zu arbeiten. Der erste Parameter mongo im Kommando bezieht sich auf den Namen des Containers.
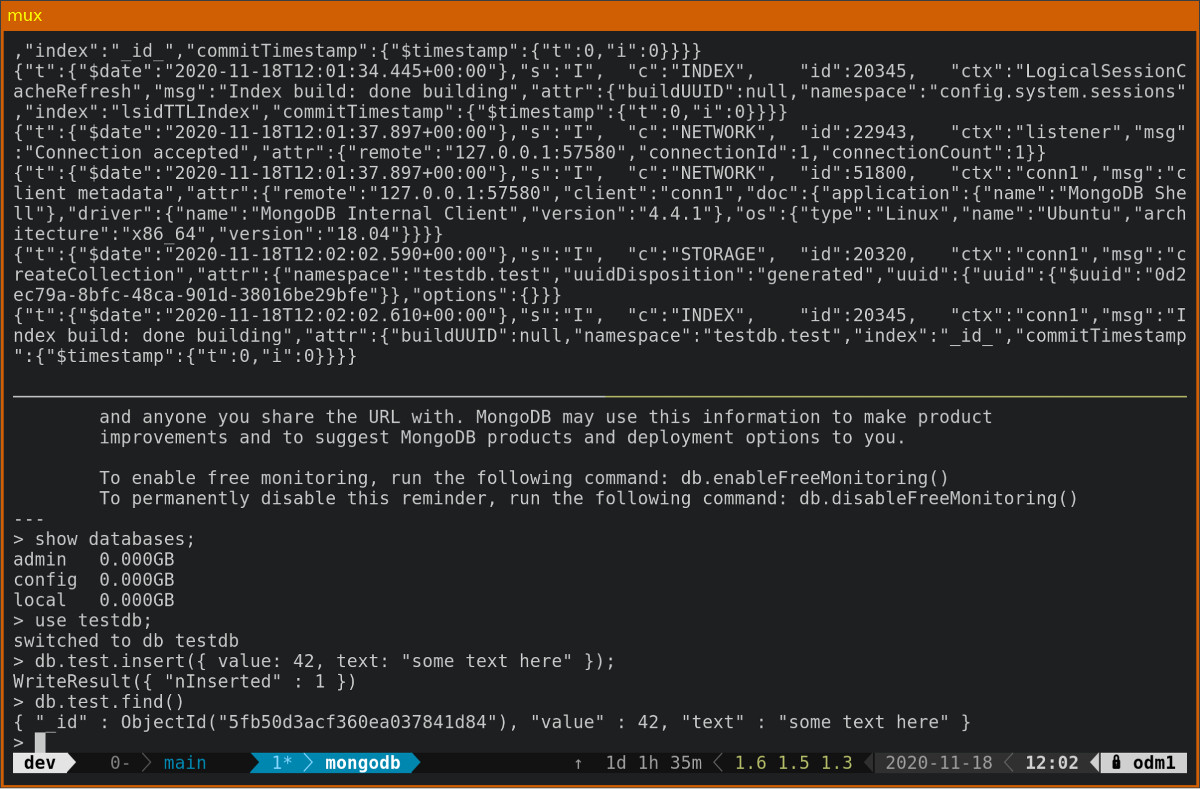
Der laufende MongoDB-Container sowie eine mongo Shell an der Entwicklungs-Kommandozeile
Eine weitere Option, mit der Sie vertraut sein sollten, ist -v. Damit können Sie ein lokales Verzeichnis oder eine Datei in einem laufenden Container abbilden. Sie sollten jeweils der Online-Dokumentation eines Images entnehmen, welche Pfade im Container verwendet werden. Unter https://hub.docker.com finden Sie Seiten für die verfügbaren Images, oder eventuell in anderen Registries, wenn Ihre Images nicht bei Docker selbst gelistet sind. Für MongoDB etwa ist der Pfad für Daten im Container /data/db. Sie können auf dem Host verschiedene Datenverzeichnisse anlegen, mit denen etwa unterschiedliche Kundenszenarien einfach austauschbar sind.
Natürlich unterstützt das Kommando docker viele weitere Optionen, und es empfiehlt sich, diese im Laufe der Zeit kennenzulernen. Allerdings lassen sich bereits viele Alltagsprobleme auf dieser Basis lösen, etwa der einfache Umstieg zwischen verschiedenen Versionen einer Serversoftware sowie der damit verarbeiteten Daten. Der nächste Schritt besteht darin, eigene Images zu erzeugen. So können Programme oder gar Shellskripte in ihrer Ausführungsumgebung gekapselt werden, und entsprechende Setups über eine Registry verteilt. Der Docker Hub bietet sich an, solange eigene Images nicht als privat betrachtet werden. Ein vollwertiger Account kostet Geld, kommt aber mit der Möglichkeit, Images privat zu halten und nur für bestimmte Anwender verfügbar zu machen. Auch die grossen Cloud-Anbieter unterstützen Docker-kompatible Registries. Ich habe etwa die AWS Elastic Container Registry zu diesem Zweck bereits erfolgreich verwendet (die Azure Container Registry finden Sie hier).
Eigene Docker-Images zur Kapselung von Anwendungen
Ich hatte einmal einige Skripte auf meinem Linux-Rechner geschrieben, mit deren Hilfe ich Formatierungen für Blogposts durchführen konnte. Da gab es ein Skript in Python, das sich die Library Pygments zunutze machte, um Code farblich hervorzuheben. Ich hatte dieses Skript aber nur auf bestimmte Blöcke anwenden wollen und daher noch ein Perl-Skript geschrieben, das in einer Markdown-Datei bestimmte Elemente heraussuchen und selektiv formatieren konnte. Zur Umwandlung von Markdown in HTML verwendete ich ein JavaScript-Modul, und als Erweiterung hierzu gab es noch ein paar Funktionen zur Handhabung unterschiedlicher Bildgrößen. Schließlich wurde GNU Make eingesetzt, um die Verarbeitung von ganzen Verzeichnishierarchien mit Markdown-Dateien zu automatisieren. Ganz schön Polyglott, dieser Ansatz – aber so ist es oft auf Unix-Maschinen, wenn Programmierer und Admins sich die verbreitetsten Systemtools zur Problemlösung zu Nutze machen, natürlich jeweils mit einer gesunden Präferenz für die ihnen jeweils am besten vertrauten Werkzeuge.
Es ergab sich nun, dass andere Anwender am Einsatz meiner Formatierungslösung interessiert waren, und manche von denen setzten nicht einmal Linux ein. Docker bot einen einfachen Weg, die gesamte Ausführungsumgebung zu kapseln und gleichzeitig systemunabhängig zu verteilen. Zur Erzeugung eines eigenen Docker-Images brauchen Sie eine Datei namens Dockerfile. Hier ist die von dem beschriebenen Projekt.
Dockerfiles sind angenehm einfach aufgebaut. Am Anfang wird mit der Anweisung FROM ein Ausgangspunkt gesetzt, in diesem Fall ein fertiges Image, in dem für die JavaScript-Teile des Projekts bereits Node enthalten ist. Mit den RUN-Anweisungen werden nun während der Erzeugung des eigenen Images Kommandos im Container ausgeführt, hier etwa zur Installation zusätzlicher Pakete mit den Paketmanagern von Debian Linux sowie Python 3. Die COPY-Kommandos übertragen Dateien vom Host in den Container, wo sie während der Image-Erzeugung persistiert werden. Die Zielpfade im Container sind weitgehend Ihnen überlassen. Natürlich empfiehlt es sich nicht, vorhandene Systemdateien zu überschreiben, aber grundsätzlich dürfen Sie die Container-Umgebung als ihr eigenes System verstehen, wo Sie allein das Sagen haben.
Dieser Gesichtspunkt ist übrigens auch interessant, um Docker und seine Images als Bausteine von Softwaresystemen zu verstehen. Kommandozeilenwerkzeuge sind unter Linux extrem leistungsfähig, und mithilfe von Docker lassen sie sich überall verwenden. Denken Sie etwa an die Funktionen von ImageMagick – Sie können an der Kommandozeile eine Kombination von Tools ausprobieren und dann zumindest als Proof of Concept dieselben Kommandos in einem Image als Backend eines Web Service einrichten.
Schließlich wird dem Image mit der Anweisung CMD ein Kommando zugewiesen, das beim Start ausgeführt wird, solange nichts anderes an der Kommandozeile festgelegt wird. Um das Image zu erzeugen, dient ein build-Kommando:
Der Parameter -t gibt den Namen des Images an, der abschließende Punkt den Pfad, in dem die Erzeugung stattfinden soll. Pfade im Dockerfile, etwa zum Kopieren von Dateien, sind relativ zum hier angegebenen Verzeichnis. Nach der Erstellung kann dieses Image lokal ausprobiert werden:
Im Beispiel ist zu sehen, dass ein lokaler Ordner im Container verfügbar gemacht wird, etwa unter dem Pfad /process. Die Skripte, die in das Image kopiert wurden, gehen entsprechend davon aus, in diesem Pfad die Dateien zu finden, mit denen sie arbeiten sollen. Es ist nicht nötig, diese Details irgendwo formell zu deklarieren – die Verwendung allein reicht aus.
Abschließend zu diesem Beispiel können Sie ein selbst erzeugtes Image auch in den Docker Hub hochladen. Dazu benötigen Sie dort einen Account, und dann verwenden Sie das Kommando docker push für den Upload. Wichtig übrigens: Docker verwendet „overlays“, also Schichten, für die Ablage von Dateien in Images. Das bedeutet, dass Ihr eigenes Image lediglich die Daten speichert, die es selbst erzeugt, während der Erstellung herunterlädt, oder modifiziert. Das Basisimage “node:latest” etwa mag auf dem Zielsystem eines Anwenders bereits verfügbar sein, und es wird direkt weiter verwendet. So bleiben die Datenmengen für einzelne Images handhabbar.
Die Kür: Mehrere Container kombinieren
Von Deployments mit Docker kennen Sie vielleicht das Tool docker-compose. Dieses Werkzeug dient der Orchestrierung, also dem Start und der Verwaltung mehrerer Container, die untereinander Abhängigkeiten haben. In komplexen Laufzeitumgebungen wird eventuell heute Kubernetes bevorzugt, weil seine Fähigkeiten im Bereich dynamischer Skalierung weiter gehen die von docker-compose. Für Entwickler ist letzteres allerdings höchst nützlich, wenn Docker-Container kombiniert werden sollen.
Ich hatte selbst mit einem Projekt zu tun, im Rahmen dessen ein Theme für eine WordPress-Site bearbeitet werden sollte. Ich wollte die PHP-Quelltextdateien gern lokal bearbeiten und das Theme testen. Dazu brauchte ich eine WordPress-Installation sowie eine MySQL-Datenbank. Statt nun mühsam die Installation dieser Komponenten auf meinem Arbeitscomputer durchzuführen, erzeugte ich eine Konfigurationsdatei für docker-compose. Das Ergebnis sah so aus:
Das Format der Datei ist YAML, es kommt also auf die Einrückung an. Sie sehen, dass zwei „services“ erzeugt werden, „db“ und „wordpress“. „db“ verwendet das Image für MySQL Version 5.7, mit einigen Umgebungsvariablen, die zur Konfiguration der Datenbank beim Start des Containers verwendet werden. Für solche Details ist wiederum die Registry-Webseite maßgeblich. Der Benutzername und das Passwort hier sind willkürlich. Sie müssen natürlich mit den entsprechenden Optionen im Block „wordpress“ übereinstimmen, aber der Sicherheit dienen sie nicht wirklich, denn der Dienst „db“ ist bei laufenden Containern nicht von aussen erreichbar.
Im Block „wordpress“ wird wiederum ein Image angegeben. Ausser den Umgebungsvariablen gibt es hier allerdings einige Elemente, die bisher nicht vorgekommen sind. Unten angefangen stehen die Ports, diese sind ebenso wie beim Kommandozeilenaufruf zu verstehen. Der Container „wordpress“ wird intern einen Dienst auf Port 80 starten, und dieser wird ebenfalls auf Port 80 des Hosts verfügbar gemacht. Noch einmal der Hinweis auf den Block „db“: hier fehlt eine Konfiguration für „ports“, was bedeutet, dass der Datenbankdienst außerhalb des Systems, das in dieser Konfigurationsdatei deklariert ist, nicht verfügbar ist.
Wie greift nun also der Dienst „wordpress“ auf den Dienst „db“ zu? Ganz einfach, das macht Docker von selbst, basierend auf der Einstellung im Block „depends_on“. Dort wird festgelegt, dass „db“ für die Verwendung von „wordpress“ aus benötigt wird, aber nebenbei sorgt dieser Eintrag auch dafür, dass von „wordpress“ aus ein Netzwerksystem namens „db“ verfügbar ist, das eben auf den anderen Container verweist. Docker richtet für diese Zwecke automatisch virtuelle Netzwerke ein, um das Gesamtsystem abzubilden.
Zum Schluss wird noch im Block „volumes“ eine Abbildung des lokalen Ordners „theme“ in einem bestimmten Pfad des laufenden Containers eingerichtet. So hat nun der laufende WordPress-Container Zugriff auf das Theme im lokalen Verzeichnis des Hosts. Mit diesem Setup kann ich lokal Dateien des Themes verändern, während der laufende Container automatisch darauf zugreift. Für andere Datenbereiche der beiden Container ist dies nicht notwendig, liesse sich aber ebenso einfach machen – etwa um bestimmte Daten für die Testinstallation von WordPress vorzuhalten.
Mit einem Aufruf an docker-compose können Sie die gesamte Struktur starten:
Die Option -d startet alles im Hintergrund. Mit docker ps können Sie die laufenden Container sehen, und mit docker-compose down alles wieder beenden. Für meine Entwicklungszwecke habe ich dieses Konzept noch mithilfe von Browsersync – einem Node-Tool – erweitert. Dazu verwende ich eine einfache Konfigurationsdatei bs-config.js:
Nun starte ich mit browser-sync start –config bs-config.js das Tool. Basierend auf der Konfigurationsdatei überwacht es die lokalen Dateien mit den relevanten Endungen im Verzeichnis theme. Das Tool erlaubt eine Browserverbindung auf Port 3000 und zeigt dort Inhalte an, die von http://localhost geladen werden – mit anderen Worten, die WordPress-Site aus dem laufenden Docker-Container. Sollten sich die Dateien im überwachten Pfad ändern, sorgt Browsersync dafür, dass der Browser entsprechend neu lädt. So ist nun die Entwicklungsumgebung für das PHP-basierte WordPress-Theme perfekt. Ich arbeite bequem lokal mit VS Code an den Dateien, und wenn ich eine Änderung speichere, lädt der Browser die Seite neu. Dabei brauche ich keine lokalen Installationen von WordPress oder MySQL, es gibt keine Konflikte mit anderen laufenden Projekten oder dergleichen. Docker macht’s möglich!
Docker im Entwickleralltag – Fazit
Ich hoffe, dass meine Beispiele in diesem Artikel Ihr Interesse an der Verwendung von Docker für Entwickleraufgaben geweckt haben. Für mich ist Docker heute ein alltägliches Werkzeug. Ich arbeite noch immer mit virtuellen Maschinen, allerdings fast ausschließlich für Windows und Entwicklungswerkzeugen wie Visual Studio, die komplexe Umgebungen erfordern und nicht in einem Container eingesetzt werden können. Von der Einsatzfrequenz her sind Container momentan für mich wesentlich wichtiger als virtuelle Maschinen. Ich wünsche viel Erfolg damit in Ihren eigenen Projekten!
Hier finden Sie weitere Artikel zum Thema:
- Interaktive Arbeit mit Docker – Eine Einführung in den Betrieb von Docker-Containern Teil 1
- Containerdaten und Backups für Docker – Eine Einführung in den Betrieb von Docker-Containern Teil 2
- Eigene Docker-Images bauen – Einführung in den Betrieb von Docker-Containern – Teil 3
- Grundlagen der Orchestrierung – Eine Einführung in den Betrieb von Docker-Containern Teil 4
- Docker Debugging: Diagnose und Behebung von gängigen Container-Fehlern

- Eine Docker-Anwendung auf einem Virtual Ubuntu-Server von Host Europe betreiben – Teil 2 - 4. November 2022
- Eine Docker-Anwendung auf einem Virtual Ubuntu-Server von Host Europe betreiben – Teil 1 - 19. Oktober 2022
- Vorbereitung eines Anwendungssystems für ein Deployment mit Docker – Tutorial - 19. Mai 2022
