Seit einiger Zeit sind Microservices das Hype-Thema auf Konferenzen. In herkömmlichen Software-Systemen trifft man immer wieder auf die gleichen Probleme. Die Codebase wird unübersichtlich, neue Features brauchen immer mehr Zeit in der Entwicklung, und die Skalierung der Anwendung frisst eine Menge Ressourcen. Microservices versprechen hier Abhilfe zu schaffen.
Das Konzept ist simpel: Teile die Anwendung in viele kleine unabhängige Einheiten, um Komplexität aufzugliedern, unabhängig zu skalieren und Wiederverwertbarkeit zu fördern. Die Microservice-Erfolgsgeschichten von Amazon, Netflix, Uber und Co scheinen die Theorie zu unterstreichen.
In der Tat hilft die Microservice-Architektur dabei, diese Probleme auf eine elegante Art zu lösen. Auf dem Weg zu einer Microservice-basierten Anwendung stellen sich einem jedoch ganz neue Hürden in den Weg. In diesem Artikel werden ein paar der Probleme, die es mit dieser Architektur zu lösen gibt, erklärt und verschiedene Ansätze besprochen.
Microservices vs Monolithen
Microservices sind ein Gegenentwurf zu der klassischen monolithischen Architektur. Bevor wir uns ihnen widmen, sollten wir jedoch klären, was eigentlich ein Monolith ist. Wer schon einmal eine Applikation entwickelt hat, wird dabei mit hoher Wahrscheinlichkeit eine monolithische Architektur gewählt haben.
Der Begriff Monolith kommt aus dem altgriechischen und bedeutet übersetzt so viel wie „einheitlicher Stein“. Wikipedia meint dazu: „Ein Monolith ist eine eher allgemeinsprachliche Bezeichnung für einen natürlich entstandenen oder bearbeiteten Gesteinsblock, der komplett aus derselben Gesteinsart besteht.“
Monolithen stellen die klassische und intuitive Art da, Software zu entwickeln. Eine Anwendung wird hier als eine Einheit entwickelt, die auf einem Technologie-Stack basiert. Beispiele hierfür sind PHP Laravel, Java Spring Boot oder auch Node.js Express Applikationen. Fachliche Abgrenzungen innerhalb der Software werden durch Module realisiert, welche durch natürliche Funktionalitäten der gewählten Programmiersprache verbunden werden, z.B. Methoden-Aufrufe:
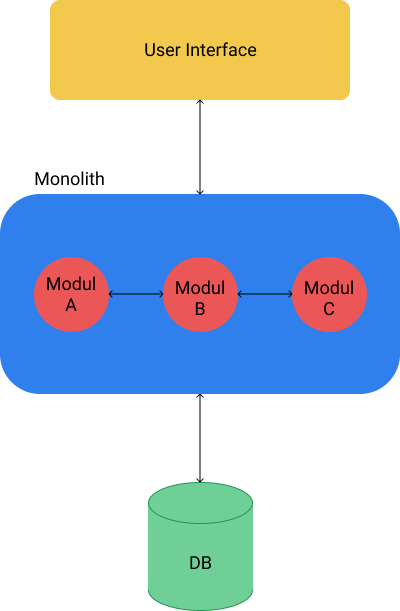
Eine klassische Monolithen-Architektur
Nachteile von Monolithen
Diese Herangehensweise ist simple und leicht umsetzbar, jedoch bietet sie auch einige Nachteile, die vor allem im späteren Stadium der Entwicklung spürbar sind:
Big Ball of Mud
Monolithische Anwendungen können im Laufe der Zeit zum “Big Ball of Mud” mutieren. Eine Situation, in der die fachliche Trennung einzelner Teile der Anwendung nicht konsequent verfolgt wurde oder die Applikation schlichtweg so groß geworden ist, dass kein Entwickler die Anwendung gänzlich erfassen und verstehen kann. Dies führt zu einer steigenden Entwicklungszeit für neue Funktionalitäten und frustrierten Entwicklern.
Sprachabhängigkeit
In einer monolithischen Anwendung ist man abhängig von dem Technologie-Stack, den man zu Beginn gewählt hat, obwohl dieser für manche Probleme nicht die ideale Lösung darstellt. Python hat sich als “State of the Art” Sprache für Machine und Deep Learning etabliert, als Backend-Sprache für Webanwendungen dominieren jedoch eher Java, C# und PHP. Bei einem reinen Monolithen muss man sich für eine der Technologien entscheiden.
Begrenzte Skalierbarkeit
Im Webbereich ist es normal, dass man ab einer gewissen Nutzerzahl die Anwendung nach oben skalieren muss. Egal welche Technologie man gewählt hat, ab einer gewissen Zahl an Anfragen ist Schluss. Die Skalierung eines Monolithen ist sehr simpel, mehrere Instanzen einer Anwendung werden auf einem oder mehreren Servern gestartet. Ein Loadbalancer kümmert sich darum, die Anfragen auf verschiedene Instanzen zu verteilen. Laut dem AKF Scale Cube handelt es sich um eine Skalierung auf der X-Achse. Der Nachteil dieser Herangehensweise sind hohe Kosten, da die gesamte Anwendung inklusive Datenbank repliziert werden muss, was zu einem hohen Ressourcenverbrauch an RAM, CPU und Speicherplatz führt.
Unzuverlässigkeit
Ein weiteres Problem mit monolithischen Anwendungen ist ihre Unzuverlässigkeit. Fehler in der Anwendung, wie beispielsweise Memory Leaks, haben das Potential, das gesamte System lahm zu legen.
Vorteile von Microservices
Microservices adressieren diese Probleme, in dem sie die monolithische Anwendung aufbrechen. Anstatt sich auf einen einzelnen Technologie-Stack zu verlassen, wird versucht, kleine unabhängige Teile des Systems zu finden, welche über eine sprachunabhängige API kommunizieren. Einzelne Services können in der am besten geeigneten Technologie entwickelt werden. Klar abgegrenzte Aufgaben ermöglichen es den Entwicklern, an einzelnen Services zu arbeiten, ohne sich mit der Komplexität des gesamten Systems auseinanderzusetzen.
Durch eine Microservice-Architektur kann ein System auf der Y-Achse des AKF Scale Cube skaliert werden. Es werden nicht von dem ganzen System mehrere Instanzen bereitgestellt, sonder nur von ressourcenreichen Services. Services, die z.B. für Machine Learning viel Rechenleistung benötigen, können auf teuren Servern mit GPU laufen, während Services mit niedrigen Anforderungen auf günstigen Hosts verbleiben.
Dies führt zu einer optimalen Nutzung der Umgebung und einer einfachen und schnellen Skalierbarkeit des Systems. Bei einer sauberen Aufteilung der Services fällt bei einem kritischen Fehler nicht das komplette System aus, sondern nur ein kleiner Teil, und die Anwendung kann immer noch genutzt werden.
Das sind alles gute Gründe für eine Microservice-Architektur, doch leider ist sie auch nicht die eierlegende Wollmilchsau. Microservices kommen mit einigen nicht zu vernachlässigenden Nachteilen. Doch bevor wir diese besprechen, schauen wir uns erst einmal ein paar der Herausforderungen an, die dieses Pattern mit sich bringt.
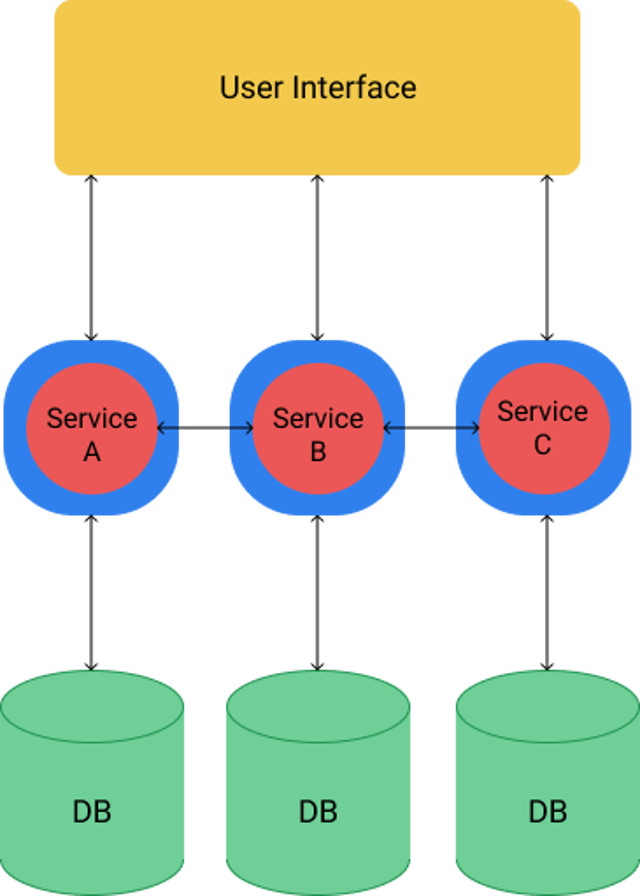
Eine klassische Microservice-Architektur
Die Microservice-Umgebung
Wenn man Software entwickelt und veröffentlicht, gibt es nichts Schlimmeres als Probleme mit der Umgebung. Konflikte in den Abhängigkeiten, zwischen verschiedenen Versionen oder Inkompatibilität zwischen verschiedenen Betriebssystemen können einen bis zur Weißglut treiben. Gottseidank gibt es für dieses Problem schon lange eine Abhilfe.
Container-Lösungen
Früher wurden Instanzen von Anwendungen in virtuellen Maschinen (VM) ausgeliefert. In einer virtuellen Maschine wird zusätzlich zu der Anwendung noch ein Betriebssystem ausgeführt.
Der Vorteil: man kann die Umgebung samt aller Abhängigkeiten festsetzen und bei Bedarf einfach sauber neu starten. Der große Nachteil ist natürlich ein gewisser erhöhter Ressourcenverbrauch. Zu monolithischen Zeiten war das noch vollkommen in Ordnung, allerdings ist der Aufwand und der Ressourcenverbrauch viel zu hoch, wenn man nicht mehr eine VM pro Applikation, sondern eine pro Service benötigt. Deshalb brauchte es noch einige Zeit bis die Microservice-Lösung wirklich praktikabel wurde, und zwar bis zu dem Siegeszug von Container-Lösungen und vor allem dem Platzhirsch Docker. Anders als virtuelle Maschinen nutzen Container den Kernel des Betriebssystems, auf dem sie laufen und sind damit viel leichtgewichtiger.
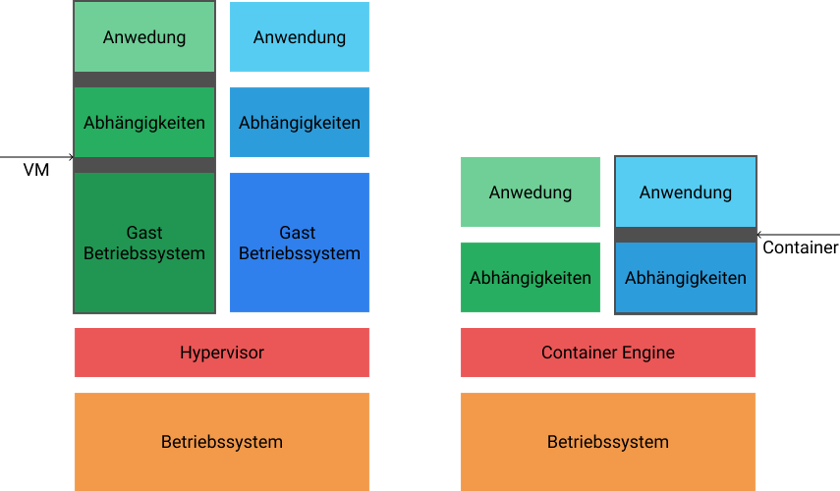
VM vs. Container
Das gesamte Docker-Ökosystem wurde mit dem Gedanken entwickelt, die Bereitstellung von Software zu vereinfachen, und den Erfolg wird wohl heute niemand mehr leugnen können. Doch nicht nur Container helfen dabei, eine Microservice-Architektur umzusetzen. Ein weiterer Grundpfeiler der Microservice-Umgebung sind Container-Orchestration-Lösungen.
Container-Orchestration und Kubernetes
Das wichtigste und bekannteste Container-Orchestrations-Werkzeug ist Kubernetes. Ursprünglich von Google unter dem Namen Borg entwickelt ist Kubernetes mittlerweile als Open Source Software verfügbar. Kubernetes ermöglicht es, mehrere Server zu einem Cluster zusammenzufügen, wobei sich Master Nodes um das Verwalten des Clusters kümmern und Worker Nodes Container ausführen. Ein Server-übergreifendes System kann in seinem idealen Zustand definiert werden, und Kubernetes wird versuchen, diesen Zustand herzustellen. In einem Cluster kann man definieren, wie viel CPU und RAM ein Container braucht, und Kubernetes verteilt die Last bestmöglich auf alle verfügbaren Nodes. Abstürzende Container werden von Kubernetes selbständig neugestartet oder ersetzt. Eine Microservice-Anwendung, die in Containern auf Kubernetes läuft, kann ideal und schnell skaliert werden. Sollten die Ressourcen knapp werden, ist es einfach, neue Nodes zum Cluster hinzuzufügen und neue Instanzen von überlasteten Services zu starten.
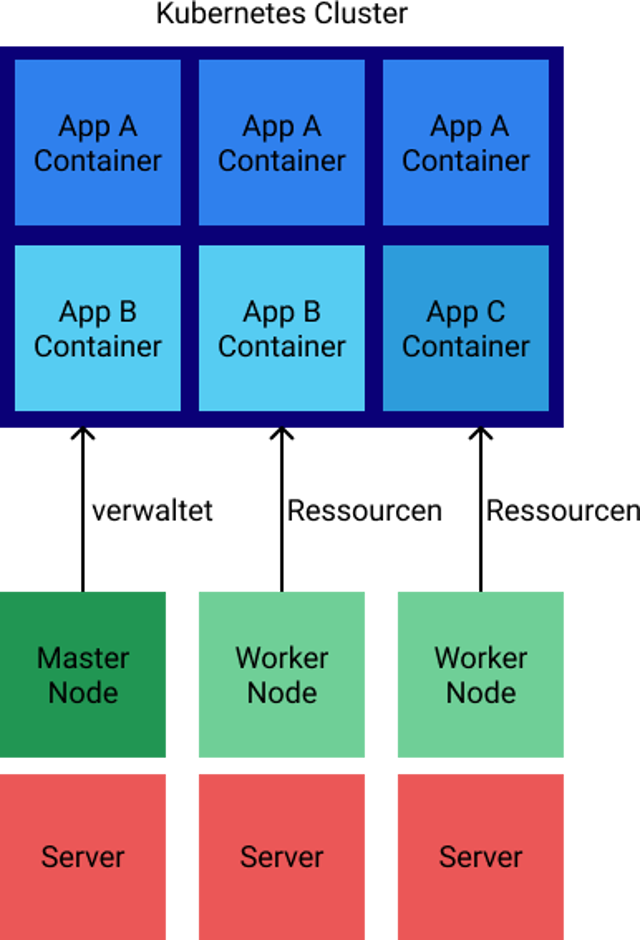
Kubernetes
Kubernetes und Docker schützen auch vor dem “Vendor Lock-In”, zu deutsch Anbietersperre. Hierbei ist es nicht mehr, oder nur sehr schwer möglich, eine Anwendung von einem Cloud-ServiceAnbieter zu einem anderen umzuziehen. Mittlerweile gibt es bei allen großen Cloud-Anbietern wie Google, Amazon und Microsoft, als auch bei vielen kleineren und spezialisierten Anbietern Kubernetes als Service. Durch die abstrahierte Umgebung, die Kubernetes liefert, ist es möglich, ohne großen Aufwand in ein neues Cluster umzuziehen.
Die Microservice-Kommunikation
Microservices reduzieren die Komplexität, da einzelne Probleme in Servicen gelöst werden können, ohne auf Seiteneffekte zu achten. Jedoch verschwindet die Komplexität nicht vollends, sondern verlagert sich zumindest teilweise in die Schnittstellen der Services. Daher ist es notwendig, diese Schnittstellen genau zu planen und die Vor- und Nachteile der verschiedenen Kommunikationsarten abzuwägen. Bei der Wahl der Kommunikation zwischen den Services kann man zwischen synchroner und asynchroner Kommunikation entscheiden.
Synchrone Kommunikation
Synchrone Kommunikation bedeutet nicht, wie im herkömmlichen Sinn, dass es sich um einen blockierenden Aufruf handelt, sondern, dass eine Anfrage geschickt und auf eine Antwort gewartet wird. In der Regel handelt es sich bei der synchronen Kommunikation um eine eins-zu-eins Kommunikation.
Diese Herangehensweise hat den großen Vorteil, dass sie sehr simpel ist und die meisten Entwickler Erfahrung auf diesem Gebiet haben. Im Moment gibt es drei populäre Ansätze für die synchrone Kommunikation in Microservices. Der Klassiker ist die Kommunikation über HTTP mit einer REST-Schnittstelle. REST ist eine Spezifikation, wie eine über HTTP kommunizierende API konzipiert werden sollte. Oftmals trifft man jedoch auch auf sogenannte REST-Like APIs, die die grundlegenden Konzepte von REST umsetzen, sich jedoch nicht an jedes Detail halten. Grundlegend werden bei dieser Form einer API HTTP-GET Anfragen genutzt, um Ressourcen anzufragen. Mit einer POST-Anfrage werden neue Ressourcen erstellt, mit PUT und PATCH werden Ressourcen geändert und schließlich mit DELETE wieder gelöscht. Jede Ressource bekommt hier einen eigenen Endpunkt, Url Parameter und Query Parameter werden genutzt, um Anfragen zu spezifizieren. Das Standard-Datenformat ist JSON. Das wohl wichtigste Konzept von REST ist die Zustandslosigkeit, d.h. es wird keine Sitzung im Backend gehalten, der gesamte Zustand wird über die Antwort definiert und im Frontend gehalten.
Eine moderne alternative zu REST ist das 2015 von Facebook veröffentlichte GraphQL. GraphQL ist, wieder der Name schon sagt, eine Query-Sprache für APIs. Die Datenstruktur ist wie ein Graph aufgebaut. Unter der Haube werden zwar immer noch Standard HTTP Anfragen genutzt, bei der Verwendung einer GraphQL-Implementierung muss man sich um diese Schicht jedoch nicht mehr kümmern. Anfragen, um Daten zu bekommen, werden in Queries abgebildet. Anfragen, die den Zustand der Daten ändern, werden als Mutations zusammengefasst. Das Dateiformat ist auch hier JSON. Die Besonderheit von GraphQL ist, dass bei Queries und Mutation die Struktur der Antwort bei der Anfrage festgelegt wird, der Aufrufer entscheidet, welche Relationen einer Ressource für ihn wichtig sind und in der Antwort enthalten sein sollen. Das führt zum einen zu einer klareren und vorauschaubaren Datenstruktur bei Anfrage und Antwort, als auch zu weniger Aufrufen und damit weniger Datenkommunikation.
{
book(id: "1") {
title
author {
firstName
lastName
}
}
}
GraphQL-Query
Hier wird eine GraphQL-Query gezeigt. Die Anfrage bezieht sich auf die Ressource “Books”, in der Antwort erwarten wir das Feld “title”, und außerdem wollen wir gleichzeitig den Autor mit Vor- und Nachnamen wissen. Folgendes Listing zeigt die Antwort auf diese Query. Man kann gut erkennen, dass sich beide Strukturen gleichen. Um an die identischen Daten von einer REST-API zu bekommen, wären zwei Aufrufe nötig gewesen (einmal an die Ressource “/book” und einmal an die Ressource “/author”). Diese beiden Aufrufe müssten dann noch in das richtige Format geparst werden.
{
"data": {
"book": "Refactoring",
"author": {
"firstName": "Martin",
"lastName": "Fowler"
}
}
}
GraphQL-Antwort
Die Felder der Query können beliebig erweitert werden. Möchte man z.B. noch das Erscheinungsjahr des Buches wissen und welche Bücher der Autor sonst noch geschrieben hat, würde die Query wie folgt aussehen:
{
book(id: "1") {
title
realiseDate
author {
firstName
lastName
Books {
title
}
}
}
}
GraphQL-Query mit Erscheinungsjahr und anderen Büchern des Autors
Die dritte populäre Methode der synchronen Kommunikation sind Remote Procedure Calls. Mit gRPC hat Google ein Framework für Remote Procedure Calls entwickelt, das mittlerweile ein Open Source Projekt und Teil der Cloud Native Foundation ist. Anfragen sehen hierbei aus wie herkömmliche Methodenaufrufe. Durch das Protocol Buffer Format ist es möglich, die Methoden und Typen für das gRPC Interface zu definieren. Der protoc Compiler generiert dann für eine Vielzahl an Programmiersprachen Service und Objekt bzw. Typen Implementierungen, die sehr einfach in eine Anwendung einbindbar sind. gRPC nutzt statt JSON ein binäres Format für den Austausch. Des weiteren gibt es auch eine eine gRPC-Web Implementierung für die Verwendung im Browser. Die stark typisierte Beschreibung und das binäre Format führen zu einer sicheren und schnellen Schnittstelle. Allerdings gibt es keine klare Trennung zwischen Datenabfragen und Zustandsänderungen, was diese Methode etwas unübersichtlicher als REST und GraphQL machen kann.
Service-Discovery
Da die Services bei der synchronen Kommunikation gegenseitig ihre Schnittstellen aufrufen, müssen sie auch wissen, wie sie sich gegenseitig erreichen können. Sie müssen also ihre gegenseitige Adresse kennen. Das ist bei Servicen, von denen nur eine Instanz existiert, noch verhältnismäßig einfach, jedoch bei einer Vielzahl an Instanzen nicht trivial.
Hierfür braucht man eine Service Discovery — eine Software, bei der sich alle neuen Service Instanzen registrieren. Wenn eine Anfrage geschickt werden soll, wird zuerst eine Liste mit allen verfügbaren Zielen abgerufen. Die Auflösung kann über zwei verschiedene Wege erfolgen:
- Client Side Discovery: Jeder Service bekommt einen eigenen Client, der zuerst die Liste abfragt und dann die Last auf verschiedene Instanzen verteilt.
- Server Side Discovery: Es gibt einen zentralen Service, der mit der Registry kommuniziert und die Lastverteilung übernimmt. Alle Anfragen werden über diesen Router geleitet.
Beide Ansätze haben ihre Vor- und Nachteile. Während bei der Client Side Discovery jedem Service ein entsprechenden Client zur Seite gestellt werden muss, was die Services aufbläht, existiert bei der Server Side Discovery ein einzelner Fehlerpunkt, der Router, der bei einem Ausfall das ganze System lahmlegen kann.
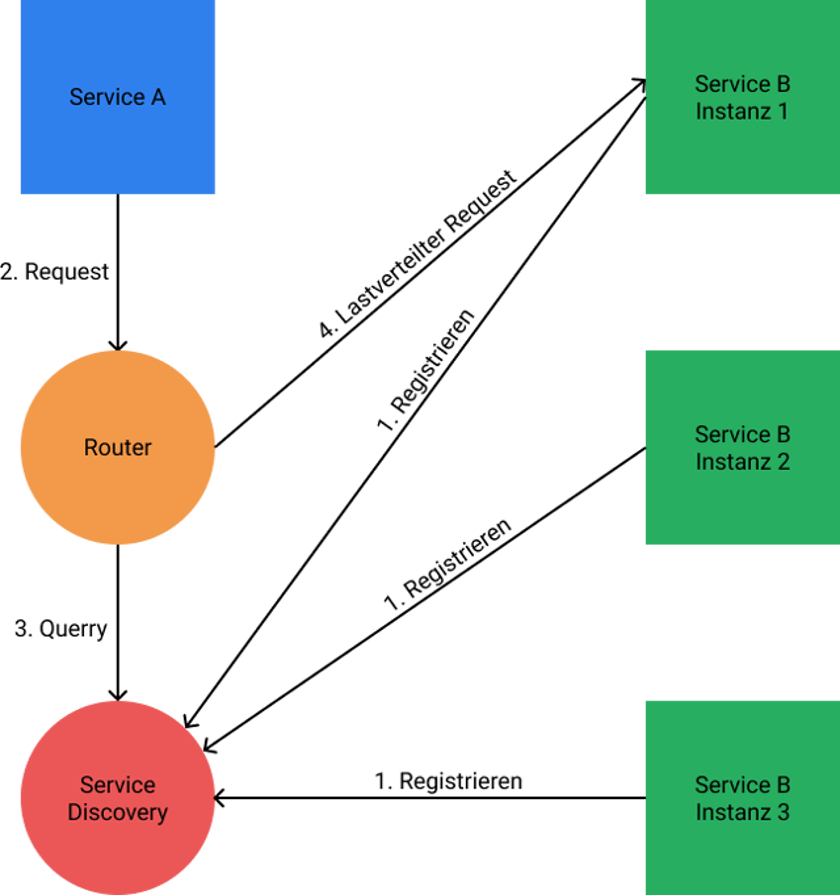
Server Side Discovery
Circuit Breaker
Doch was passiert wenn eine Service-Instanz doch einmal ausfällt? Dies kann fatale Folgen für die gesamte Anwendung haben. Während einzelne Services noch auf die Antwort des ausgefallenen Service warten, kommen bereits neue Anfragen in das System. Diese neuen Anfragen stauen sich auf und lösen Fehler in Abhängigkeiten des ausgefallenen Service aus, was potentiell das gesamte System lahmlegt.
Hier kommt der Circuit Breaker ins Spiel. Der Circuit Breaker überwacht alle Instanzen einzelner Services. Falls eine Instanz eine festgelegte Fehlerrate überschreitet, fliegt die Sicherung. In diesem Fall wird der Circuit Breaker alle Anfragen sofort mit einem Fehler beantworten, um dem ausgefallenen Service die Möglichkeit zu geben, sich zu erholen. Nach einer gewissen Zeit wird die Sicherung auf halb offen geschaltet, das heißt einige Anfragen werden testweise weitergeleitet. Sollten die Anfragen erfolgreich sein, wird die Sicherung wieder geschlossen. Im anderen Fall wiederholt sich der Prozess, bis der Service wieder verfügbar ist.
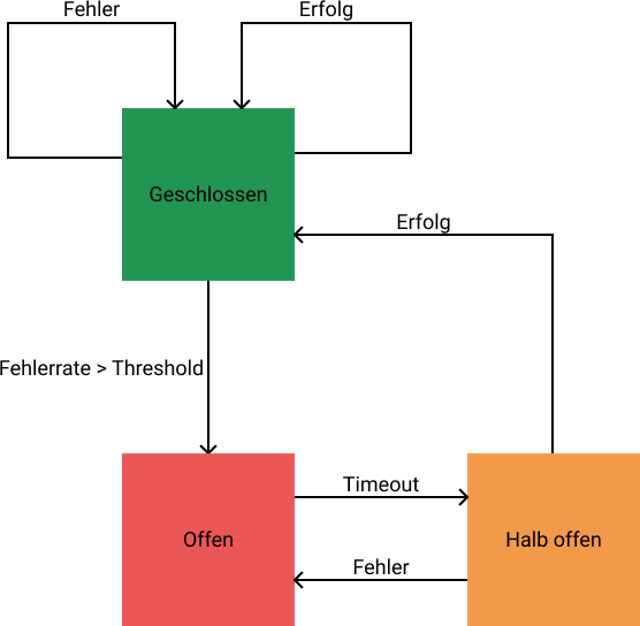
Circuit Breaker
Asynchrone Kommunikation
Asynchrone Systems besitzen einen zentralen Bus, auf dem Nachrichten ausgetauscht werden. Anders als bei der synchronen Kommunikation wird hier nicht auf jede Anfrage eine Antwort erwartet. Services schicken Nachrichten auf einen zentralen Nachrichtenkanal. Jeder Service, der an einer Nachricht interessiert ist, liest sie und verarbeitet sie weiter. Hierbei ist es nicht ungewöhnlich, dass eine Nachricht von mehreren Teilnehmern gelesen wird.
Message Broker
Für die Kommunikation ist ein sogenannter Message Broker verantwortlich. Die beiden bekanntesten Message Broker sind wohl RabbitMQ und Apache Kafka. RabbitMQ ist ein wenig leichtgewichtiger als Apache Kafka, wobei letzterer mittlerweile, dank seiner Features und seiner Stabilität, bei den meisten großen Firmen vertreten ist.
Bei der Verwendung eines Message Broker wird die Verantwortlichkeit innerhalb des Systems umgedreht. Services werden nicht mehr von anderen aufgerufen, sondern schicken Nachrichten auf den Message Broker, ohne zu wissen, wer diese Nachrichten weiter verarbeitet. Das einzige, was ein Service-Team wissen muss, ist welche Nachrichten der Service verarbeiten muss und welche er senden muss.
Sollten neue Services implementiert werden, muss am System nichts angepasst werden, da die Nachrichten bereits geschickt werden. Der neue Service muss einfach nur auf die für ihn interessanten Themen hören. Eine Service Registry ist ebenfalls nicht von nöten. Da die Services gegenseitig sowieso nichts von ihrer Existenz wissen, können sie einfach darauf vertrauen, alle Informationen an den Broker weiterzugeben. Auch ein Circuit Breaker wird mit ausgereiften Brokern wie Apache Kafka nicht mehr benötigt. Wenn eine Service-Instanz ausfällt, bleibt die Nachricht in der Warteschlange, bis sie von einer anderen oder der wieder gestarteten Instanz bearbeitet werden kann.
Asynchrone Kommunikation und Message Broker klingen wie ein Allheilmittel gegen alle Probleme, die die Microservice-Architektur mit sich bringt Jedoch muss man auch hier Vor- und Nachteile abwägen. Das größte Problem mit Message Brokern ist die zusätzliche Komplexität, sowohl in der Entwicklung als auch in der Wartung.
Apache Kafka und RabbitMQ bieten zwar eine gute Integration für die meisten Programmiersprachen, jedoch wird der Programmierstil, der für diese Architektur nötig ist, für die meisten Entwickler unbekannt und unintuitiv sein. Jedes Microservice-Team muss sich initial mit einer neuen Technologie, die nicht gerade trivial ist, auseinandersetzen, und erfahrene Entwickler in diesem Bereich sind im Moment noch rar. Der zweite große Nachteil ist, dass ein Message Broker eine zentralen Fehlerpunkt darstellt. Sollte der Broker ausfallen, ist keinerlei Kommunikation zwischen den Servicen mehr möglich.
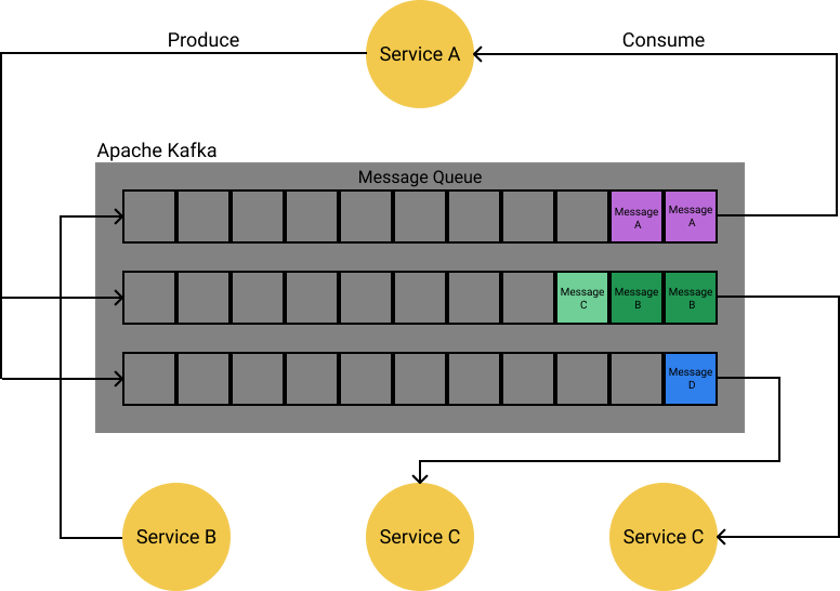
Apache Kafka
Service Mesh
Doch auch, wenn man sich nicht für einen Message Broker entscheidet, gibt es neue Technologien, die einige Probleme in der synchronen Kommunikation auf elegante Weise lösen.
Eine dieser Technologien ist das sogenannte Service Mesh mit seinem populärsten Vertreter Istio. Istio ist ein Open Source Projekt, welches vornehmlich von Google, IBM und Lyft entwickelt wird. Klassisch besteht ein synchron kommunizierendes Microservice-System aus vielen Komponenten, die in die einzelnen Services mit eingebaut werden müssen, wie z.B. der Circuit Breaker oder ein Router, der sich um das Load Balancing und die Service Registry kümmert. Dies bläht die Service unnötig auf, und es müssen auch gute Lösungen für alle Technologie-Stacks im System existieren.
Istio verfolgt einen anderen Ansatz — es stellt eine Umgebung für Microservices bereit, in der jedem Service ein Proxy zur Seite gestellt wird. Dieser Proxy sitzt zwischen dem Service und der Kommunikation mit dem System. Anstatt mit anderen Servicen direkt zu kommunizieren, fängt der Proxy alle Anfragen ab und übernimmt die wichtigen Aufgaben im System, ohne dass Änderungen am Service direkt notwendig sind. Istio und die Service Proxy übernehmen folgende Funktionen:
- Routing zwischen Servicen und Instanzen
- Load Balancing
- Policy System für Zugriffsberechtigungen und Rate Limiting
- Automatische Metriken und Logs
- Kommunikationsverschlüsselung

Istio Service Proxy
Istio verfügt über eine zentrale Einheit, in der das Service Mesh konfiguriert werden kann. Es läuft auf Kubernetes und unterstützt im Moment HTTP, gRPC, WebSocket und TCP.
Fazit — Microservices, die Grundlagen und Technologien
Wie wir gesehen haben, bieten Microservices einige Herausforderungen, deren Lösung oftmals nicht ganz einfach ist und wohl überlegt sein will. Auch sind viele Lösungen nicht exklusiv. In vielen Fällen ist es durchaus sinnvoll, Istio neben Apache Kafka für die Kommunikation zu betreiben, jedoch muss die Komplexität des Systems dies auch rechtfertigen.
Microservices sind keine Blaupause für die Softwareentwicklung per se, monolithische Anwendungen werden auch in Zukunft ihre Daseinsberechtigung haben. Die Entscheidung zwischen dem Monolithen und den Microservices sollte immer daran festgemacht werden, wie groß eine Anwendung voraussichtlich wachsen wird.
Sollte man planen, eine Anwendung über mehrere Jahre zu warten und weiterzuentwickeln, wird sich jedoch die Microservice-Architektur auf lange Sicht durch ihre zahlreichen Vorteile auszahlen. Ein Ansatz, den viele Architekten mittlerweile verfolgen, heißt “Monolith-First”. Das heißt, eine neue Anwendung wird bis zu einem gewissen Punkt als Monolith entwickelt, um schnell Ergebnisse liefern zu können, um dann später den Monolithen und neue Funktionen in Microservices aufzuteilen.

- Microservices — Grundlagen und Technologien von verteilter Architektur - 19. Dezember 2019
