Systemressourcen, Speicherverwaltung, Treiber, Threads, Nebenläufigkeit, Interrupts. Gleich vorweg: Alles Begriffe, mit denen ich persönlich in meinem Entwickleralltag weniger direkten Kontakt habe, denn Rust ist im Kern eine Low-Level Systemprogrammiersprache, und mein typisches Arbeitsumfeld ist die Web-Entwicklung.
Ich bin sehr vertraut mit JavaScript, TypeScript, Node und gängigen Bibliotheken und Frameworks wie Angular, Vue und React. In dieser schönen neuen Welt der Webentwicklung ist vieles hip, modern, leichtgewichtig, noch schnelllebiger. Das alles wird dann noch mit einem Werkzeugkasten voller toller Hilfsmittel und einer riesigen Community ergänzt. Natürlich halten mich mein persönlicher Werdegang, aber auch dieses spezielle Umfeld, in dieser komfortablen Welt und auf einigem Abstand zum Thema der systemnahen Programmierung und Sprachen wie C, C++, Go oder eben auch Rust.
Dieser Artikel stellt nun einen zutiefst subjektiven Blick auf die Programmiersprache Rust dar. Auf den didaktisch besten Einstieg in die Sprache selbst möchte ich an dieser Stelle verzichten (denn die offizielle Dokumentation bietet hier schon exzellente kostenfreie Möglichkeiten), sondern vielmehr aus meiner Sicht interessante Aspekte beleuchten, die mich hellhörig werden lassen, wenn ich den Namen Rust höre. Überdies können wir in diesem Rahmen nicht alle Bestandteile der Sprache erwähnen und manche nur oberflächlich streifen. Wir beginnen mit einem kleinen Beispiel, welches wir durch die nennenswerten Bestandteile von Rust sukzessive erweitern.
Die ersten Schritte
Zur Installation und Verwaltung der aktuellen Rust-Version nutzt man am besten Rustup. Ähnlich wie beim Node Version Manager kann man darüber Rust initial installieren, updaten oder zwischen Versionen wechseln. Folgen wir der Anleitung auf der Webseite haben wir in der Kommandozeile anschließend u.a. die Befehle rustc und cargo verfügbar. Den Rust-Compiler rustc nutzen wir selten alleinstehend, denn Dreh- und Angelpunkt eines Rust-Projekts ist vielmehr der Befehl cargo.
Cargo
Ähnlich zu npm in der Webentwicklung ist cargo sowohl ein Paketmanager, aber auch ein Werkzeug, um Rust-Projekte aufzusetzen, zu kompilieren, zu starten, zu testen oder um Dokumentation zu generieren (siehe Aufruf cargo –help). Über Cargo können wir mit folgendem Befehl ein erstes Projekt erstellen:
cargo new u-rest-u-rust # Projekt erzeugenDies erzeugt einen Ordner für unser Projekt mit dem Namen u-rest-u-rust, in dem sich schon ein paar Dateien befinden. Ohne diese im Detail anzuschauen, wechseln wir in den Ordner, kompilieren das Projekt und lassen es mit folgendem Aufruf erst einmal laufen:
cd u-rest-u-rustcargo run
Wir sehen (Abbildung 1) einen kurzen Kompiliervorgang, die Erzeugung einer Binärdatei (z.B. u-rest-u-rust.exe auf Windows) und die Ausgabe des altbekannten Hello, world!.
Wenn auch im Moment noch sehr simpel, erinnert dies alles an den klassischen Einstieg in ein Web-Projekt, z.B. mit der Angular CLI. Über ein Manager-Programm, hier cargo, setzt man das Projekt auf oder führt projektbezogene Befehle aus. Fühlt sich sehr bequem und vertraut an.

Abbildung: Erste Ausgabe von cargo run mit obligatorischem “Hello World”.
Entwicklungsumgebung
Gleich wollen wir uns den Inhalt unseres Projekts genauer ansehen. Natürlich kann man auch in der Kommandozeile und z.B. dem vim Editor arbeiten, ich persönlich bin allerdings sehr gerne mit Visual Studio Code unterwegs. Fügt man dem schlanken, kostenfreien Editor von Microsoft noch die Rust-Extension (der offiziellen rust-lang Community) hinzu, hat man bereits Syntax-Highlighting und alle Code-Tools, die man fürs Erste benötigt, beisammen.

Finden Sie jetzt Ihre Wunsch-Domain.
- Große Auswahl an günstigen Domain-Endungen.
- Keine verdeckte Kosten.
Projektstruktur
Schauen wir nun in unseren Ordner u-rest-u-rust hinein, sehen wir bereits ein paar Dateien und Ordner (Abbildung).
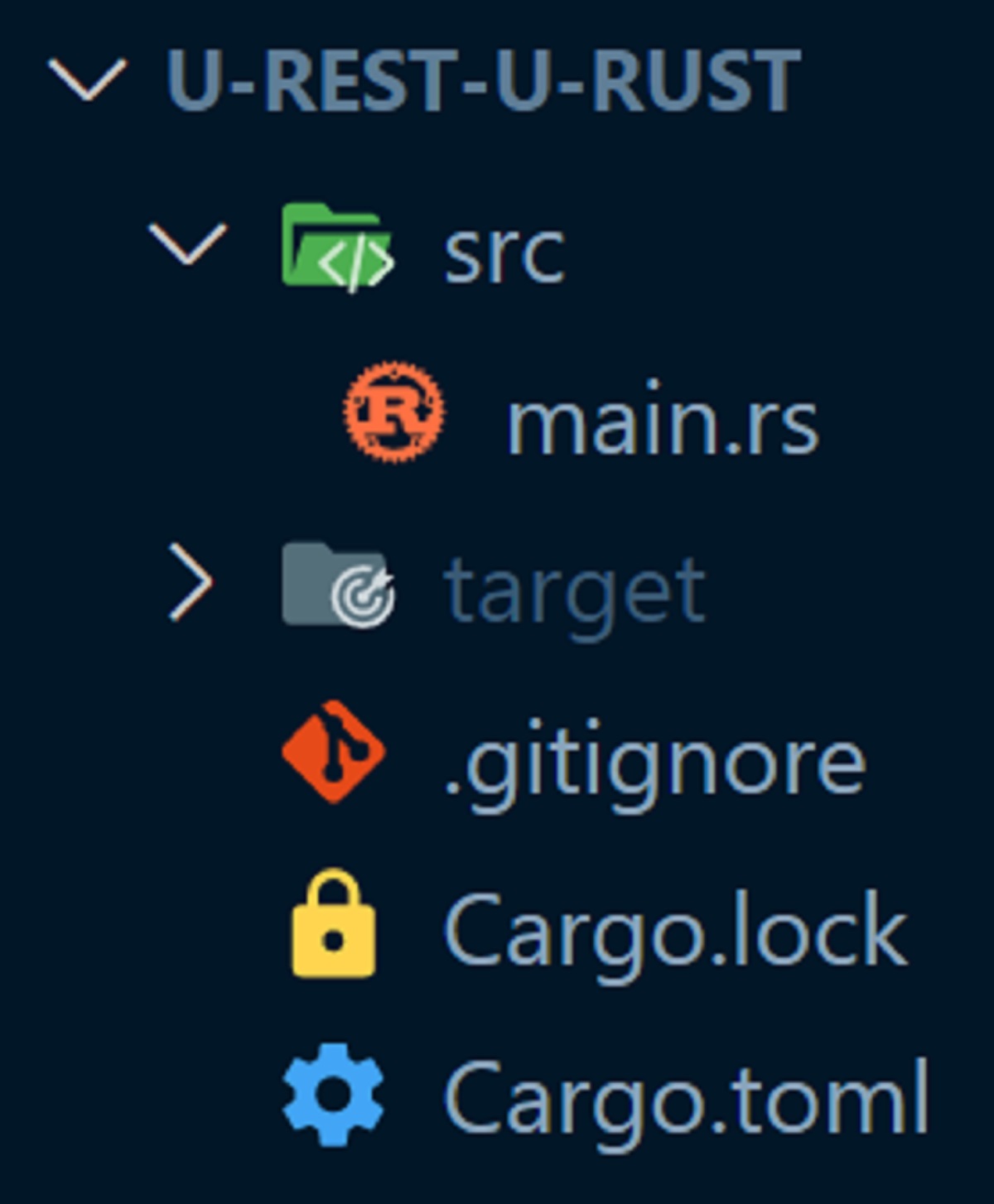
Abbildung: Inhalte eines initialen Rust-Projekts.
Standardmäßig ist ein Rust-Projekt über Git versioniert und enthält minimal eine .gitignore-Datei, die generierte Compiler-Artefakte von der Versionierung ausschließt. Das Kompilat befindet sich unter dem Ordner target, der automatisch bei cargo run bzw. cargo build (nur Kompilieren ohne Ausführung) erzeugt wird. Weiterhin gibt es das Datei-Paar Cargo.toml und Cargo.lock, welches, ähnlich wie die package.json und package-lock.json bei NPM, die Meta-Informationen und Abhängigkeiten des Projekts enthält.
Aktuell gibt es noch keine Abhängigkeiten. Möchte man eine externe Bibliothek nutzen, so kann man z.B. lokale oder Verweise auf GitHub setzen, oder man schaut sich auf crates.io um, welches eine breite Palette an Community-Bibliotheken bietet. Dies erinnert stark an die vielen Möglichkeiten der Web-Community über NPM. Möchten wir beispielsweise das Paket (bei Rust auch crate genannt) rand zur Generierung von Zufallswerten unserem Projekt hinzufügen, tragen wir es im Abschnitt dependencies zuzüglich der gewünschten Version ein:
Kompilieren wir nun unser Projekt erneut, können wir in der Ausgabe erkennen, dass die crate inklusive all ihrer transitiven Abhängigkeiten heruntergeladen und kompiliert wird, damit wir in unserem Code die Funktionen davon nutzen können. Analog zu NPM müssen wir uns nicht mühselig selbst um das Auflösen aller Abhängigkeiten kümmern. Die schlussendlich genutzten Versionen werden in der Cargo.lock eingetragen.
Kommen wir nun zum spannenderen Teil, dem eigentlichen Quellcode, der standardmäßig unter dem Ordner src abgelegt ist.
Grundkonzepte und Besonderheiten
Aus nur drei Zeilen besteht unsere Code-Datei main mit der Endung rs, enthält aber bereits einige Konzepte:
- Funktionen werden in Rust mit dem Schlüsselwort fn eingeleitet.
- Der Rückgabetyp kann vom Rust-Compiler (ähnlich wie es beispielsweise in TypeScript der Fall ist) in vielen Fällen anhand des Quellcodes abgeleitet werden (sogenannte Typ-Inferenz) und muss hier nicht explizit angegeben werden.
- In diesem Fall handelt es sich um den Unit-Typ (explizit geschrieben als fn main() -> ()), in anderen Sprachen auch als void bekannt.
- Ausdrücke, die keine weiter zu verwendeten Werte zurückliefern (also z.B. Variablen-Deklarationen oder Funktionen, deren Rückgabewert ignoriert wird – sozusagen einfache Instruktionen), wie unsere Konsolenausgabe, werden immer mit einem Semikolon abgeschlossen.
- Makros, wie hier println!, werden über ein Ausrufezeichen gekennzeichnet. Ein Makro ist, vereinfacht gesagt, eine Textersetzung, bei der die Makro-Funktion mit einem bestimmten Code-Schnipsel ersetzt wird. In der Nutzung sind Makros ähnlich wie in C, jedoch bietet Rust deutlich mächtigere Werkzeuge, um beispielsweise die Fehleranfälligkeit zu reduzieren.
Ein strikter Compiler
Wir könnten das Beispiel so erweitern, dass wir beispielsweise das zuvor installierte rand-Paket nutzen, um eine Zufallszahl zu generieren und stattdessen diese ausgeben:
Anhand dieser Programmzeilen, lassen sich weitere Aspekte der Sprache beschreiben:
- Ähnlich zu import-Statements in JavaScript kann man externe Abhängigkeiten über das Schlüsselwort use in sein Programm aufnehmen. Dabei kann man, wie hier, nur bestimmte Einzelteile aus dem Paket nutzen oder auch mit dem Wildcard-Operator * ganze Teilbereiche. Möchte man alle gängigen Standardfunktionen eines Pakets einbinden, so bieten diese häufig die Prelude-Konvention an. Dazu müssten wir folgendes schreiben und könnten so die gängigsten Features nutzen: use rand::prelude::*;
- Variablen werden mit let deklariert. Dabei sind diese zunächst immer unveränderlich (immutable), einmal zugewiesen, können sie nicht mehr verändert werden. Kann sich der Wert auf irgendeine Art und Weise ändern, muss man die Variable explizit mit mut als veränderbar (mutable) kennzeichnen. In vielerlei Hinsicht, z.B. in Bezug auf nebenläufige Programmierung, erfordern Datenstrukturen, die veränderbar sind, einen achtsameren Umgang. Aus diesem Grund bildete Rust diese bewusste Entscheidung, Variablen veränderlich zu machen, durch die Sprache ab.
- In unserem Fall zwingt uns der Compiler den Zufallszahlengenerator rng als mutable zu markieren, da die von uns verwendete Funktion gen_range auf einer veränderbaren Referenz operieren möchte (vermutlich weil das Erzeugen eines Wertes den internen Zustand des Generators ändert).
- Dieser Funktion können wir einen Bereich (Range) von Zahlen übergeben, die wir praktischerweise mit start..ende schreiben können, wobei das Gleichheitszeichen am rechten Ende bedeutet, dass der angegebene Wert inklusive ist (standardmäßig würde die 3 nicht mehr dazugehören).
- Unter anderem lokale Variablen und Funktionen werden typischerweise (nach Rust-Styleguide) in snake_case geschrieben, so auch unsere num_changes, die den einmal für unseren Programmlauf erzeugten Zufallswert unveränderlich enthält.
- An dieser Stelle zwar durch die Typ-Inferenz nicht notwendig, aber möglich, ist die explizite Angabe eines Typen für diese Variable. Da hier nur die Zahlen 1-3 enthalten sein können, reicht ein 8-Bit großer Integer-Wert ohne Vorzeichen bereits (u8) aus. Würde unsere Range beispielsweise über 255 hinausgehen, so würde der Compiler diesen Typ nicht zulassen.
- Zuletzt geben wir unsere Zufallszahl eingebettet in unseren Ausgabe-Text durch geschweiften Klammern auf der Konsole aus. Hier sind auch ausgefallenere Format-Optionen möglich.
Es ist gut möglich, dass die Reihe an verschiedenen Konzepten, die in so einem kleinen Beispiel versteckt sind, eine große mentale Hürde darstellen. Rust ist bekannt dafür, dass die Lernkurve doch recht steil ist. Bemerkenswert sind aus meiner Sicht jedoch, dass sich die Syntax im Grunde wie ein Mix verschiedener weit verbreiteter Sprachen wie C, Java, JavaScript, TypeScript und Python liest. Gängige Anforderungen, wie beispielsweise das Erzeugen der Zahlenbereiche, sind direkter Bestandteile der Sprache (und müssen nicht durch Schleifen und Hilfsvariablen simuliert werden). Es existiert ein Rust-Styleguide, der einem bestimmte Schreibweisen, Patterns und Konventionen an die Hand gibt (die sogar beim Verstoß als Warnung vom Rust-Compiler angezeigt werden).
Einer der größten Unterschiede zu anderen Sprachen, der gerade zu Beginn jedoch als sehr hinderlich empfunden werden könnte, ist wohl der sehr strikte Compiler. Das Versprechen von Rust ist, dass jegliches sogenanntes undefiniertes Verhalten (wie es beispielsweise in C leicht entstehen kann) verhindert wird. Der Compiler erlaubt es beispielsweise nicht, dass man über Speichergrenzen hinaus schreibt, mit Zeigern arbeitet, die in nicht mehr gültige Bereiche zeigen oder einfach nur auf einen null-Pointer nutzt. Dies geht sogar so weit, dass der Compiler diese Striktheit auch auf multithreaded Programme und dort Thread-übergreifende Speicherzugriffe ausweitet.
Testing als fester Bestandteil
Um die Funktionalität unseres Programms durch Unit-Tests sicherzustellen, ist keine Installation eines Test-Frameworks oder ein aufwendiges Aufsetzen einer geeigneten Umgebung notwendig. Zunächst lagern wir einen Teil unserer Funktionalität aus:
Den Rückgabe-Wert unserer Funktion geben wir mit -> an. Zu erkennen ist dabei eine weitere Besonderheit, die Anfangs sehr gewöhnungsbedürftig sein mag: Zwar hat Rust ein return Schlüsselwort, jedoch lässt man dieses in Rust typischerweise weg und lässt die Zeile nicht mit einem Semikolon enden, was das gleiche Resultat hat.
Schreiben wir nun einen einfachen Unit-Test für unsere Funktion, um zu prüfen, dass immer entweder eine 1, 2 oder 3 als Wert zurückgegeben wird. Dazu genügt es, eine Test-Funktion zu schreiben, in der wir die Makros !assert_eq bzw. !assert_neq nutzen und die Funktion mit einem sogenannten Attribut dekorieren:
Um alle Tests in unserem Projekt auszuführen, nutzen wir das Kommando cargo test, welches alle mit dem Test-Attribut gekennzeichneten Funktionen ausführt (siehe folgende Abbildung).
Durch das Markieren der Test-Funktionen kann Rust diese beim Erstellen eines ausführbaren Programms erkennen und kompiliert sie nicht mit in das Ergebnis. Dieses Vorgehen erlaubt es uns, die Tests sehr nah an der eigentliche Funktionalität unseres Codes zu platzieren und somit auch gut die Funktionsweise zu dokumentieren. Darüber hinaus gibt es aber auch die Möglichkeit, ganze Test-Suites pro Modul und eher Integrationstest-artige Strukturen zu bauen. Aber auch dies ist ohne zusätzliche externe Hilfsmittel möglich.
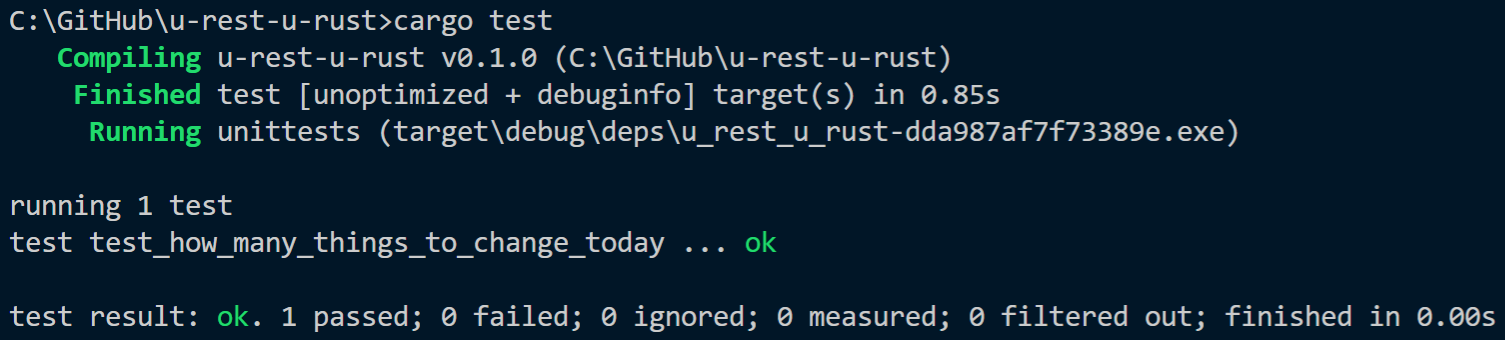
Abbildung: Ausgabe bei Ausführen der Unit-Tests mit cargo test.
Dokumentation als fester Bestandteil
Durch gute Struktur, Benennung und Tests lässt sich Quellcode ohne zusätzliche Informationen bereits gut verstehen. Häufig, gerade aber auch bei Bibliotheks-artigem Code, der für andere zur weiteren Verwendung gedacht ist, möchte man jedoch zusätzliche Dokumentation zur Verfügung stellen. Hier bietet Rust ebenso integrierte Möglichkeiten. Einfache Entwickler-Kommentare lassen sich wie in vielen anderen Sprachen mit // einleiten. Öffentlich einsehbare Kommentare in Rust schreibt man mit ///. Annotiert man eine Funktion mit solch einem Kommentar und führt anschließend cargo doc –no-deps –open aus, so extrahiert Rust diese Dokumentationskommentare, erzeugt eine HTML-Dokumentationsseite und öffnet diese im Standard-Browser (Abbildung 4).
Dies entspricht beispielsweise der gleichen Vorgehensweise wie JSDoc bzw. TSDoc, nur dass man sich bei Rust kein eigenes Dokumentations-Werkzeug suchen und dieses in sein Projekt integrieren muss. Diese Arbeit übernimmt der Werkzeugkasten von Rust.
Dies entspricht beispielsweise der gleichen Vorgehensweise wie JSDoc bzw. TSDoc, nur dass man sich bei Rust kein eigenes Dokumentations-Werkzeug suchen und dieses in sein Projekt integrieren muss. Diese Arbeit übernimmt der Werkzeugkasten von Rust.
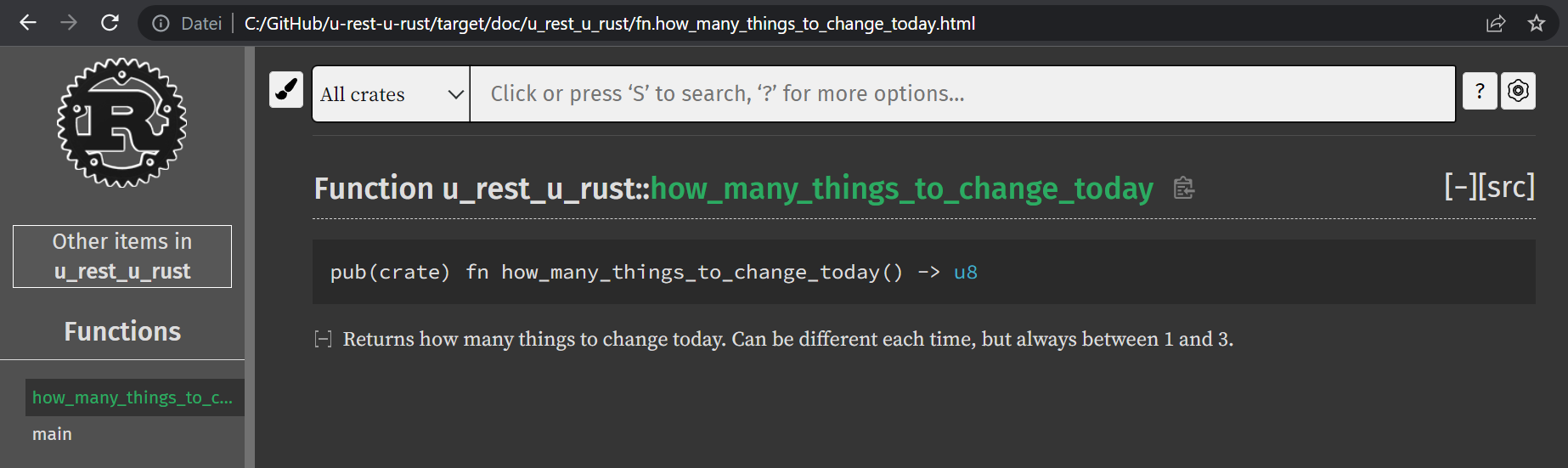
Abbildung: Generierte Dokumentationsseite unseres Beispielprojekts.
Fehlerbehandlung und Pattern-Matching
Eine weitere Besonderheit in Rust ist die Fehlerbehandlung. Anders als in vielen anderen Hochsprachen gibt es hier nicht das Konzept der Exceptions. Aber wie geht man dann mit Fehlern um? Beginnen wir unser Beispielprogramm so zu ändern, dass wir statt nur zufällig eine Zahl zu generieren, die ersten 1-3 Zeilen aus einer Datei lesen und diese ausgeben.
Legen wir im Hauptverzeichnis die Datei changes.txt mit folgendem Inhalt an:
Drink tea instead of coffeePut on different colored socksDon't use any social mediaTake the bikeGo to bed early
Als nächstes möchten wir diese Datei einlesen. Für IO-Operationen bietet Rust das komfortable std::fs-Paket (welches stark an das Node-Modul fs erinnert), wobei wir mit der Funktion read_to_string kleinere Dateien unkompliziert einlesen können. Diese Operation könnte potentiell fehlschlagen: Die Datei könnte nicht existieren, es könnten Lese-Rechte fehlen, etc. Statt dass man den Aufruf nun mit einem try-catch-Block umgibt (den man genauso gut vergessen könnte), liefert Rust hier immer einen Result-Typ zurück. Dieser enthält entweder das Ergebnis als String oder aber einen Fehler vom Typ io::Error. Das Besondere dabei ist, dass der Rust-Compiler dafür sorgt, dass man immer eine Fehlerbehandlung durchführen muss:
In der Funktion read_changes rufen wir das Einlesen der Datei auf. Wir können nun nicht einfach eine Zuweisung durchführen, sondern müssen den Result-Typ entsprechend behandeln. In diesem Fall tun wir das über das sogenannte Pattern-Matching. Das Schlüsselwort dazu lautet match. Anders als ein aus anderen Sprachen bekanntes switch-Statement kann match auch direkt in Kombination mit einer Zuweisung verwendet werden. Das Ergebnis passt entweder auf den Typ Result::Ok(T), wobei T den eingelesenen Text repräsentiert, oder auf Result::Err(E), wobei E der oben genannte IO-Error ist. In erstem Fall geben wir den Wert direkt an die Variable weiter und führen die Zuweisung durch. Im Fehlerfall schreiben wir eine Fehlermeldung auf die Konsole und brechen das Programm ab.
Das Pattern-Matching in Rust ist immer vollständig, d.h. alle möglichen Fälle müssen abgedeckt werden. In diesem Beispiel muss irgendeine Art von Fehlerbehandlung (hier der manuelle Programmabbruch) durchgeführt werden. Durch dieses Fehler-Konzept kann es nicht vorkommen, dass die Fehlerbehandlung vergessen wird. Man könnte zwar mit is_ok() prüfen, ob das Ergebnis fehlerlos ist und dann mit ok() an das Ergebnis kommen, jedoch ist der Typ dann kein String, sondern ein Option<T>, d.h. er könnte auch statt dem gewünschten Wert None enthalten (nämlich dann, wenn ein Fehler auftritt). Man wäre wiederum in der Programmierung gezwungen, mit den entsprechenden Ergebnissen umzugehen. Mag einem dieses Vorgehen anfangs geschwätzig vorkommen, so merkt man aber schnell, dass Zugriffe auf Unerwünschtes nicht mehr passieren und mögliche Fehler unterbunden werden. Der gesamte mögliche Programmfluss wird expliziter.
Ownership
Auch wenn die vollständige Erläuterung des nächsten Konzepts den Rahmen dieses Artikels sprengen würde, soll das Thema Ownership hier zumindest skizziert werden. Wenn vom Programm allokierter Speicher nicht mehr benötigt wird, muss er irgendwann wieder freigegeben werden, damit dieser nicht ungenutzt liegen bleibt und Ressourcen blockiert. Dabei ist darüber hinaus darauf zu achten, dass er nur genau einmal freigegeben wird und auch nicht fehlerhafterweise in Speicherbereiche geschrieben wird. In C++ ist dies alles Aufgabe des Programmteils, der den Speicher benötigt. Gerade bei komplexen Abläufen kann dies jedoch schnell fehlerhaft werden. Dem Entwickelnden wird hier eine große mentale Last und Disziplin aufgeladen. Rust hat zum Ziel, diese explizite Speicherverwaltung in die Sprache zu verlagern.
Kurz gesagt kann es in Rust nur genau einen Besitzer (Owner) eines Speicherbereichs geben. Der Speicher zu einer Variablen wird freigegeben, sobald diese einen Code-Block (Scope) verlässt. Da dies eine zu starke Einschränkung wäre, kann der Besitzanspruch jedoch übertragen werden (Move) oder man leiht eine Referenz auf das Objekt (Borrow).
Sehen wir uns hierzu ein kleines Beispiel an. Zunächst stellen wir unseren Code so um, dass wir die Ausgabe in eine eigene Funktion print_things_to_chage auslagern.
Soweit funktioniert noch alles, wenn wir unser Programm mit cargo run starten. Als nächstes wollen zusätzlich zur Konsolenausgabe die gleiche Liste in eine Datei schreiben:
Wollen wir diesen Code nun ausführen, erhalten wir einen Compiler-Fehler (Abbildung 5).
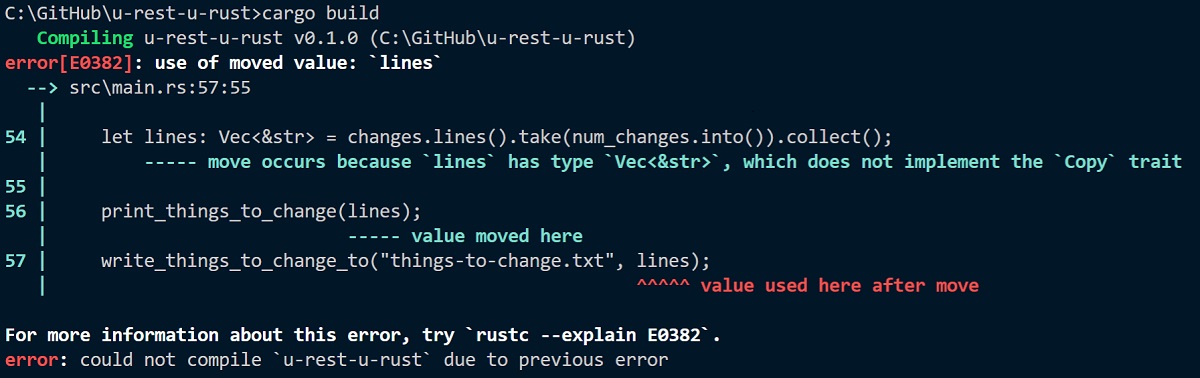
Abbildung: Compiler-Fehler aufgrund fehlender Ownership.
Bemerkenswert ist an dieser Stelle auch die Ausführlichkeit dieser Fehlermeldung: Offensichtlich fand ein sogenannter Move von lines in Zeile 56 statt, und daher können wir, laut Compiler, den Wert in der darauffolgenden Zeile 57 nicht verwenden.
Um zu verstehen, warum das ein Fehler ist, schauen wir uns den Programmfluss genauer an: Zu Beginn ist der Besitzer von lines die Funktion main (da die Variable dort angelegt wurde). Der Aufruf der ersten print-Funktion sorgt dafür, dass nun der Speicherbereich von lines an diese übergeben wird; die Ownership wechselt. Innerhalb dieser Funktion wird nun der Speicher durch die Variable things verwendet. Mit Ende der Funktion endet auch der Scope, der zugeordnete Speicherbereich wird freigegeben und die Funktion verlassen. Zurück in der main-Funktion steht nun der Speicherbereich allerdings nicht mehr zur Verfügung und lines kann deswegen nicht an die write-Funktion übergeben werden.
Es gibt nun mehrere Möglichkeiten dies zu lösen. Wir können den Speicherbereich aus der print-Funktion wieder zurückgeben (siehe folgendes Code-Beispiel). Dabei müssen wir einen Rückgabetyp definieren und empfangen den Wert wiederum in einer Variable (hier wieder lines). Gewöhnungsbedürftig mag erscheinen, dass wir dabei den gleichen Variablennamen verwenden können (sogenanntes implizites Shadowing). In Rust hat diese Schreibweise manche Vorteile, z.B. macht es den Move hier einfacher, und wir müssen keine neue Variable anlegen (es handelt sich ja ohnehin um das gleiche Element).
Eigentlich brauchen beide Funktionen jedoch diese Art des Zugriffs nicht. Statt den kompletten Vektor jeweils per Move in die Funktion zu geben, genügt es, wenn wir hier nur eine Referenz (annotiert durch &) übergeben. Da wir den Vektor nicht verändern, sondern nur lesend darauf zugreifen, wäre das auch die zu bevorzugende Umsetzung:
Dadurch, dass wir nur eine Referenz übergeben, leihen wir den Speicherbereich (Borrow) lediglich aus. Denn im Gegensatz dazu, dass es nur einen Besitzer geben darf (wobei auch nur der in der Lage ist, den Speicherbereich zu verändern), kann es beliebig viele geben, die den Speicherbereich leihen (ihn aber auch nicht verändern dürfen).
Auch wenn dies nur ein Minimal-Beispiel ist, zeigt es, dass das Ownership-Konzept zu Beginn komplex erscheinen mag. Es bringt jedoch den entscheidenden Vorteil, dass es nicht zu der Situation kommen kann, dass Code auf Speicherbereiche zugreift, die nicht mehr existieren oder keine zwei Programmteile den gleichen Bereich schreibend nutzen, er ihnen sozusagen beiden gleichzeitig gehört. Der Compiler stellt durch die Ownership zu jeder Zeit sicher, dass der Speicherbereich immer nur einem Programmteil zugeordnet ist.
Ausblick
Neben den hier vorgestellten Bestandteilen der Sprache gibt es noch deutlich mehr erwähnenswerte, die wir hier aufgrund des Umfangs nicht alle erläutern können, wie z.B. sogenannte Traits und generische Typen, Enums, Closures sowie die Themen Nebenläufigkeit und asynchrone Programmierung. Beginnt man mit Rust zu entwickeln, nähert man sich diesen Themen zwangsläufig Stück für Stück an. Hier sei wieder auf die gute kostenfreie Dokumentation verwiesen.
Die Programmiersprache Rust – Fazit
Die Entwicklung mit systemnahen Sprachen wie beispielsweise C++ hat mich durch das auf mich archaisch wirkende Umfeld, das auf sich Alleingestelltsein und die extreme Disziplin und Fehler-Intoleranz, die man bei der Programmierung an den Tag legen muss, immer etwas auf Distanz gehalten.
Die Schöpfer:innen von Rust haben sich dies zu Herzen genommen und mir eine Sprache geliefert, die vieles davon obsolet erscheinen lässt. Ich fühle mich wohl in dieser modern anmutenden Umgebung, der Unterstützung durch die Sprache und die Werkzeuge drum herum. Ich habe das Gefühl mich angstfreier, effizienter und leichtgewichtiger auch komplexen Herausforderungen in der Systemprogrammierung stellen zu können und diese bewältigen zu können.
Zuletzt macht es mir dadurch persönlich Spaß, mit Rust zu entwickeln. Ich habe Lust auf mehr und bin hungrig nach der nächsten performance-kritischen, schwierigen Aufgabe auf einem ressourcenbegrenzten Gerät.
Titelbild: Unsplash – Danial Igdery

- Komfortable Reaktivität mit Angular Signals: So schreiben Sie einfacher performanten Code - 11. April 2024
- Die Programmiersprache Rust – ein Erfahrungsbericht - 1. August 2022
- Ein tragfähiges Design-System mit Storybook.js erschaffen - 3. Februar 2022
