Continuous Integration (und sein großer Bruder Continuous Deployment) ist aus der modernen Softwareentwicklung nicht mehr wegzudenken. Ich selbst kann mich noch mit Schrecken daran erinnern, mit welchen Schmerzen ein Release Anfang der 2000er Jahre verbunden war. Das Bauen der Anwendung auf einem lokalen Entwicklerrechner war immer verbunden mit der Hoffnung, dass nicht doch irgendwelche privaten Konfigurationen Einfluss auf den Build genommen haben. Von der Möglichkeit, automatisch neue Versionen zu bauen, hatte niemand von uns auch nur zu träumen gewagt.
Dank moderner Continuous Integration Server sind viele dieser Probleme heutzutage zum Glück verschwunden (oder zumindest deutlich kleiner geworden). Doch auch Tools und Werkzeuge, die wir für Continuous Integration verwenden, entwickeln sich weiter. War früher der selbst verwaltete und geradezu liebevoll gepflegte selbst aufgesetzte Jenkins Server der Stolz eines jeden Entwicklungsteams, so sind wir inzwischen wieder einen Schritt weiter. Auch unsere Continuous Integration Umgebungen sind – wie viele andere Werkzeuge auch – in die Cloud gewandert.
Die Vorteile liegen auf der Hand: Keine manuellen Software-Updates mehr, und auch die Hardware skaliert problemlos mit wachsenden Anforderungen. Eine Handvoll Produkte tummeln sich inzwischen auf dem Markt. In diesem Artikel möchte ich einen Blick auf CircleCI werfen, das ich mit meinem Team nutze, um alle unsere Softwareprodukte zu bauen und zu verteilen.
Disclaimer: Ich stehe in keiner vertraglichen Beziehung zu CircleCI und erhalte für das Schreiben dieses Artikels keinerlei Zuwendungen (finanzieller oder sonstiger Natur) von CircleCI. Ich finde schlicht und ergreifend den Service gut.
Continuous Integration mit CircleCI – Beispielanwendung
Um den Ablauf eines Builds in CircleCI zu nutzen, werden wir eine Beispielanwendung referenzieren, anhand derer wir die einzelnen Schritte des Build-Prozesses nachverfolgen werden. Da es eine einfache Möglichkeit ist, eine Webanwendung schnell zum Laufen zu bringen, werden wir hierzu Ruby on Rails verwenden. Die Beispiele lassen sich aber sehr einfach auch auf andere Technologien übertragen.
Da CircleCI, wie wir später noch detaillierter sehen werden, eine sehr einfache Integration mit GitHub bereitstellt, nehmen wir weiterhin an, dass der Quellcode unserer Anwendung in einem GitHub Repository vorliegt.
Als Bauen unserer Anwendung verstehen wir nun einen Workflow, der die folgenden Schritte beinhaltet:
- Auschecken der Sourcen aus dem GitHub Repository.
- Installieren aller Abhängigkeiten, die unsere Anwendung benötigt.
- Ausführen des Linting-Processes, der überprüfen soll, ob der geschriebene Code die Best Practices und Codevorgaben unseres Entwicklungsteams erfüllt.
- Ausführen der Unit-Tests, die sicherstellen sollen, dass unsere Anwendung korrekt funktioniert.
- Erstellen eines Docker-Containers , der die gesamte Anwendung inklusive der benötigten Runtime enthält.
- Bereitstellen des Docker Containers in Docker Hub.
Ein reales Projekt wird möglicherweise noch zusätzliche Schritte benötigen, doch für unseres Beispiel soll dies als Liste von Anforderungen genügen. Sehen wir uns also nun an, wie wir diesen Prozess mit CircleCI aufsetzen können.
CircleCI
Account Setup
Wie bereits erwähnt, bietet CircleCI eine sehr enge Integration mit GitHub, daher erfolgt die Einrichtung eines Account sowie Anmeldung bei CircleCI auch direkt über GitHub:
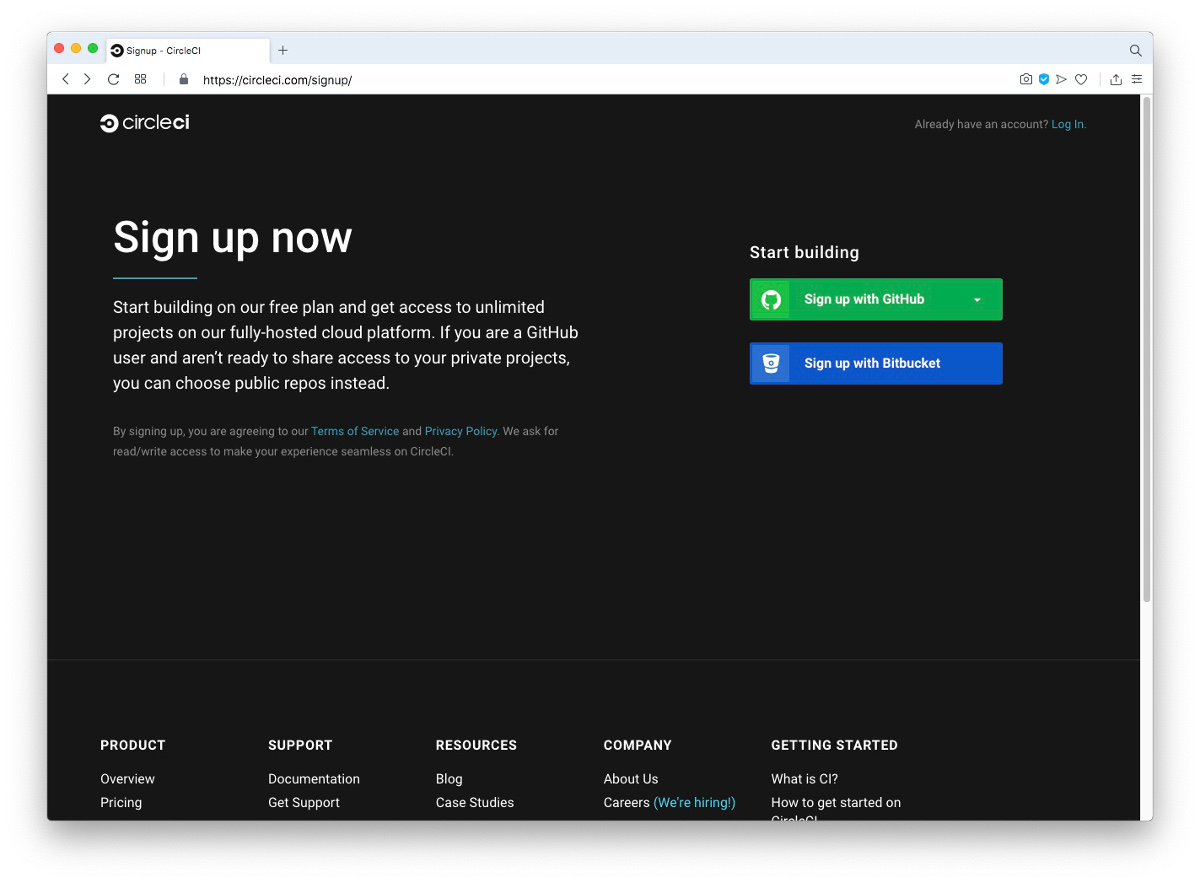
Bei der initialen Anmeldung wählen wir die Option “Sign up with GitHub” und gelangen im Anschluss zur Anmeldung bei GitHub.
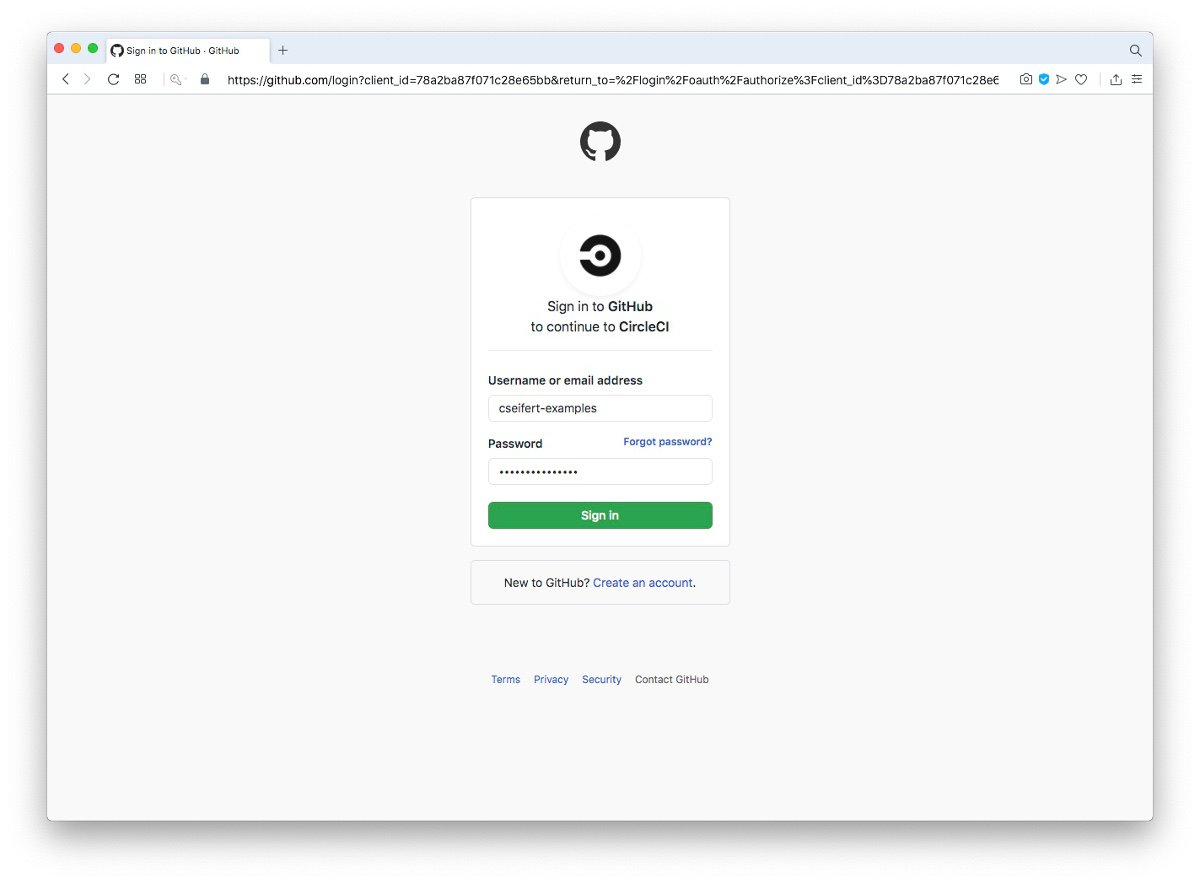
Ist dieser erfolgreich, so müssen wir noch die entsprechenden Berechtigungen erteilen, so dass CircleCI auf unsere Repositories zugreifen kann:
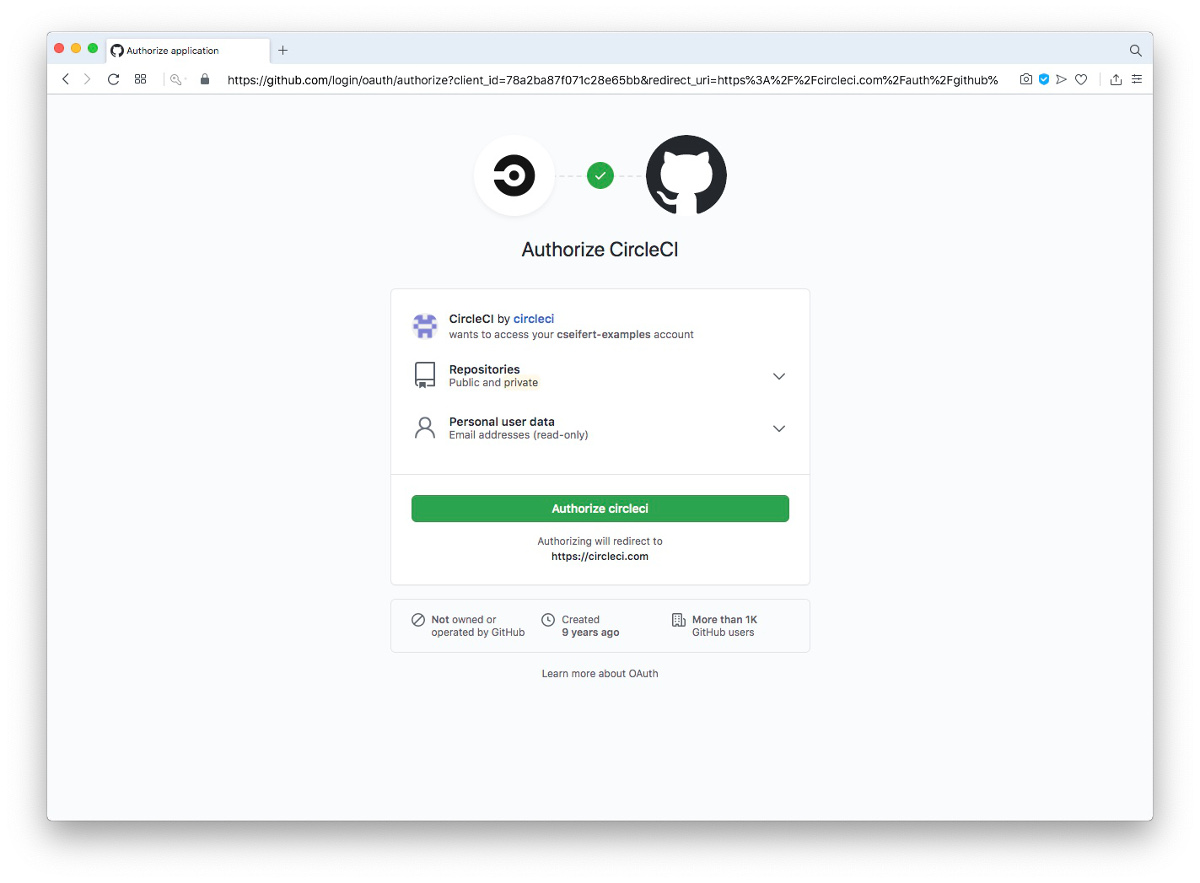
Nach der Erteilung der Rechte ist unser Account eingerichtet. Wir sehen bereits alle in unserem GitHub Account vorhandenen Projekte (in diesem Falle ist es lediglich unser Beispielprojekt) und können nun CircleCI anweisen, die einzelnen Projekte zu managen. Durch die Anmeldung haben wir automatisch den “Free” Plan von CircleCI aktiviert. Dieser erlaubt es, kostenlos einen Build-Job gleichzeitig auszuführen. Weitere Pläne erlauben mächtigere Features, für unsere Einführung genügt der “Free” Plan jedoch vollkommen.
Continuous Integration mit CircleCI – Minimalkonfiguration und Projekt-Setup
Den oben skizzierten Workflow müssen wir nun in eine Bauanleitung für CircleCI übersetzen. Dies geschieht über eine CircleCI Konfigurationsdatei, die im GitHub Repository unter “.circleci/” hinterlegt werden muss.
Beginnen wir mit der denkbar einfachsten Konfiguration.
Hier erkennen wir bereits die Struktur, nach der eine CircleCI Konfiguration strukturiert ist, und die Elemente, die in der Konfiguration verwendet werden: Workflows, Jobs und Steps. Jobs sind vielleicht die wichtigsten konzeptionellen Elemente. Ein Job definiert eine Sequenz von Aktionen, die den eigentlichen Build-Prozess definieren. Diese Sequenz besteht aus einzelnen Steps. Ein Step ist die kleinste Einheit, in der wir Aktionen definieren können, die während des Builds ausgeführt werden.
Im obigen Beispiel erkennen wir bereits zwei Steps:
- Der checkout-Step sorgt dafür, dass die Inhalte des GitHub Repositories ausgecheckt werden und für alle folgenden Steps zur Verfügung stehen.
- Der run-Step führt ein generisches Kommando auf der unterliegenden Plattform aus. In unserem Beispiel lassen wir einfach den Text “Hello world” ausgeben.
Workflows schließlich aggregieren Steps zu größeren Bausteinen. Wir werden hierauf später noch zurückkommen, für den Moment wollen wir uns auf Jobs und Steps konzentrieren.
Ein Job innerhalb von CircleCI läuft immer innerhalb eines Executors. Ein Executor definiert die Umgebung (die “Maschine”), in der die einzelnen Schritte innerhalb eines Jobs – die Steps – ausgeführt werden.
In unserem Beispiel haben wir einen docker-Executor definiert, der das Image circleci/ruby:2.6 verwendet. Wir weisen hiermit CircleCI an, die Ausführung des Jobs build (und aller darin enthaltenen Steps) innerhalb eines Docker Containers durchzuführen, der das Image circleci/ruby:2.6 verwendet. Den einzelnen Steps stehen damit alle Ressourcen zur Verfügung, die in dieses Docker Image inkludiert wurden. CircleCI stellt bereits eine ganze Reihe an vorgefertigten Images für die typischen Programmiersprachen zur Verfügung, es können hier jedoch auch beliebige weitere Docker Images verwendet werden. Der eigenen Kreativität sind daher, was das Ausgestalten der Umgebung, in welcher der Build stattfinden soll, kaum Grenzen gesetzt.
Der docker-Executor ist für viele Projekte sicherlich der am besten passende Executor, da sich hier schnell, einfach und komfortabel neue Umgebungen definieren lassen.
CircleCI bietet jedoch noch weitere Executor-Typen an, die wir für diese Einführung aber nicht näher betrachten werden. Um nun CircleCI mitzuteilen, dass das GitHub-Projekt aktiv gemanaged werden soll, klicken wir in der CircleCI “Projects” Übersicht auf den Button “Set Up Project” für unser Beispielprojekt.
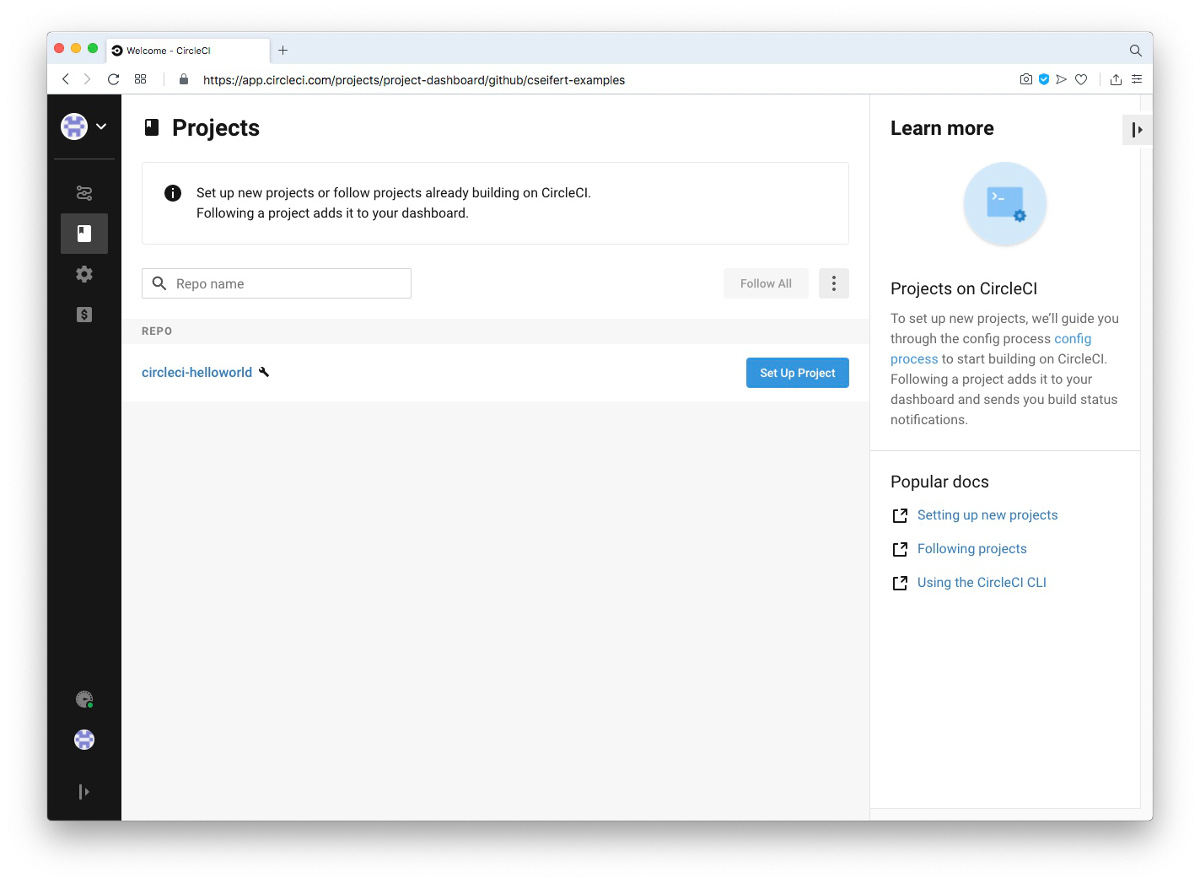
CircleCI stellt uns jetzt vor die Wahl, ob wir eine von CircleCI generierte Konfiguration in unser Projekt übernehmen oder eine eigene Konfiguration bereitstellen wollen. Da wir bereits eine eigene Konfigurationsdatei im Projekt eingecheckt haben (und die vorgeschlagene generierte Konfiguration typischerweise wenig hilfreich für ein spezielles Projekt ist), wählen wir hier die Option “Add Manually”.
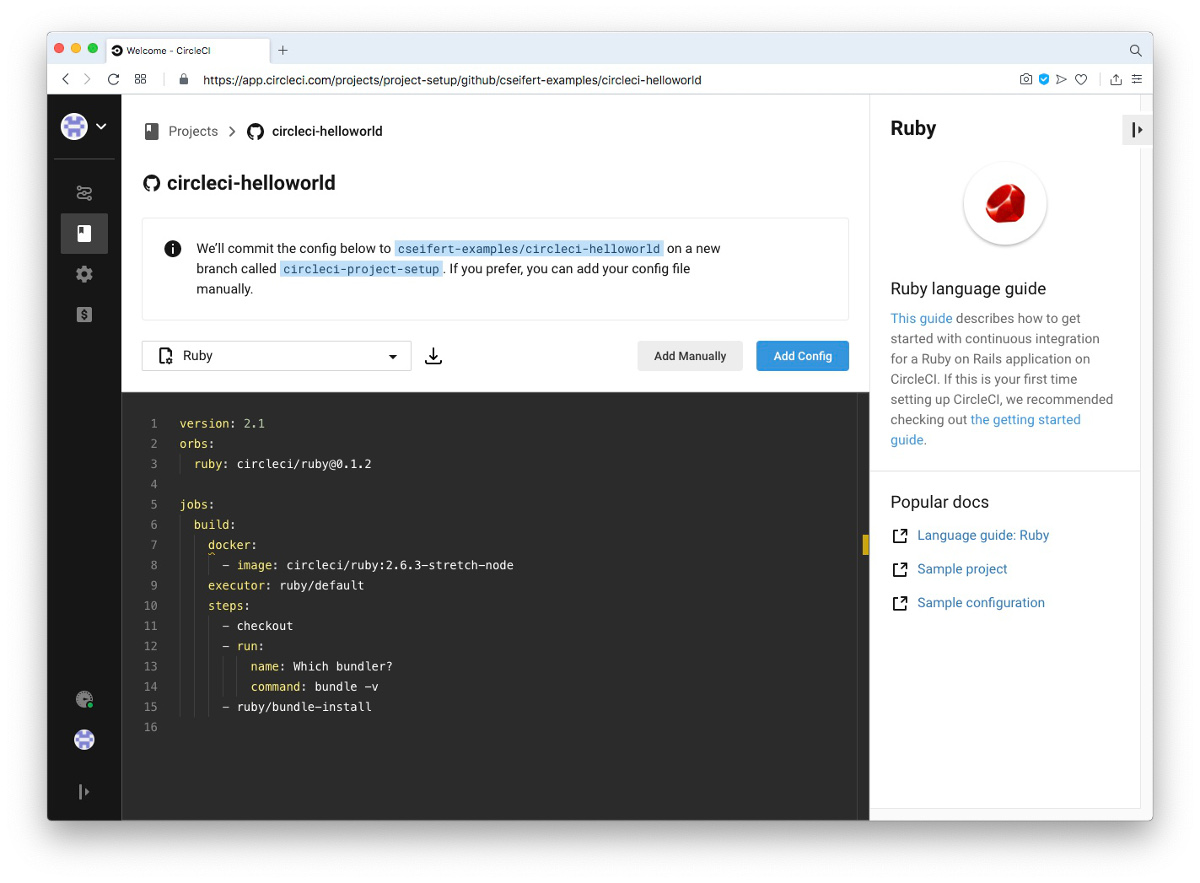
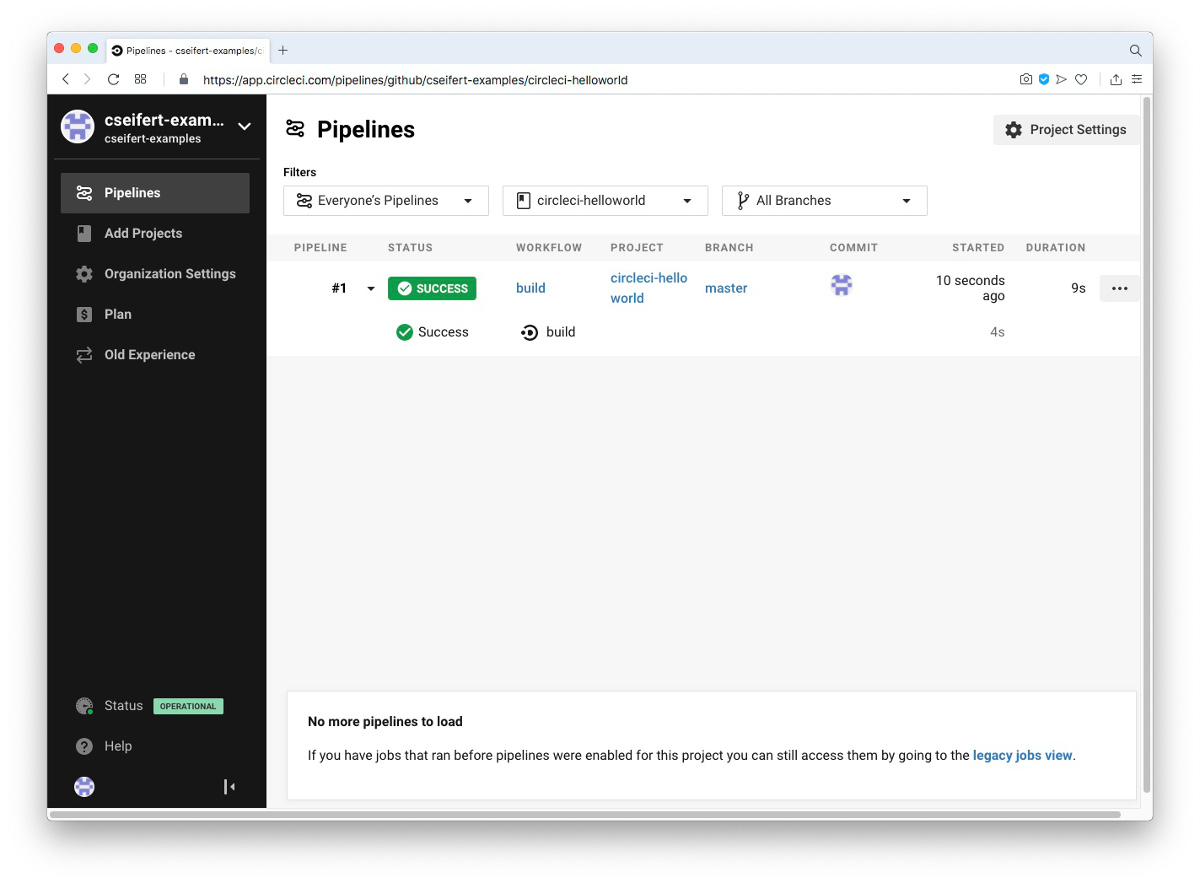
Hiermit ist das Setup für unser Projekt bereits abgeschlossen, und CircleCI startet den initialen Build, basierend auf der eingecheckten Konfigurationsdatei.
Durch die Integration von CircleCI mit GitHub wird CircleCI ab jetzt bei jeder Änderung innerhalb des Projekts (genauer bei jedem Push von neuen Commits in das Repository) informiert und, basierend auf unserer aktuellen Konfiguration, bei jedem Push einen Build unseres Projektes starten. Sehen wir uns nun etwas detaillierter den Output des gerade beendeten Builds an:
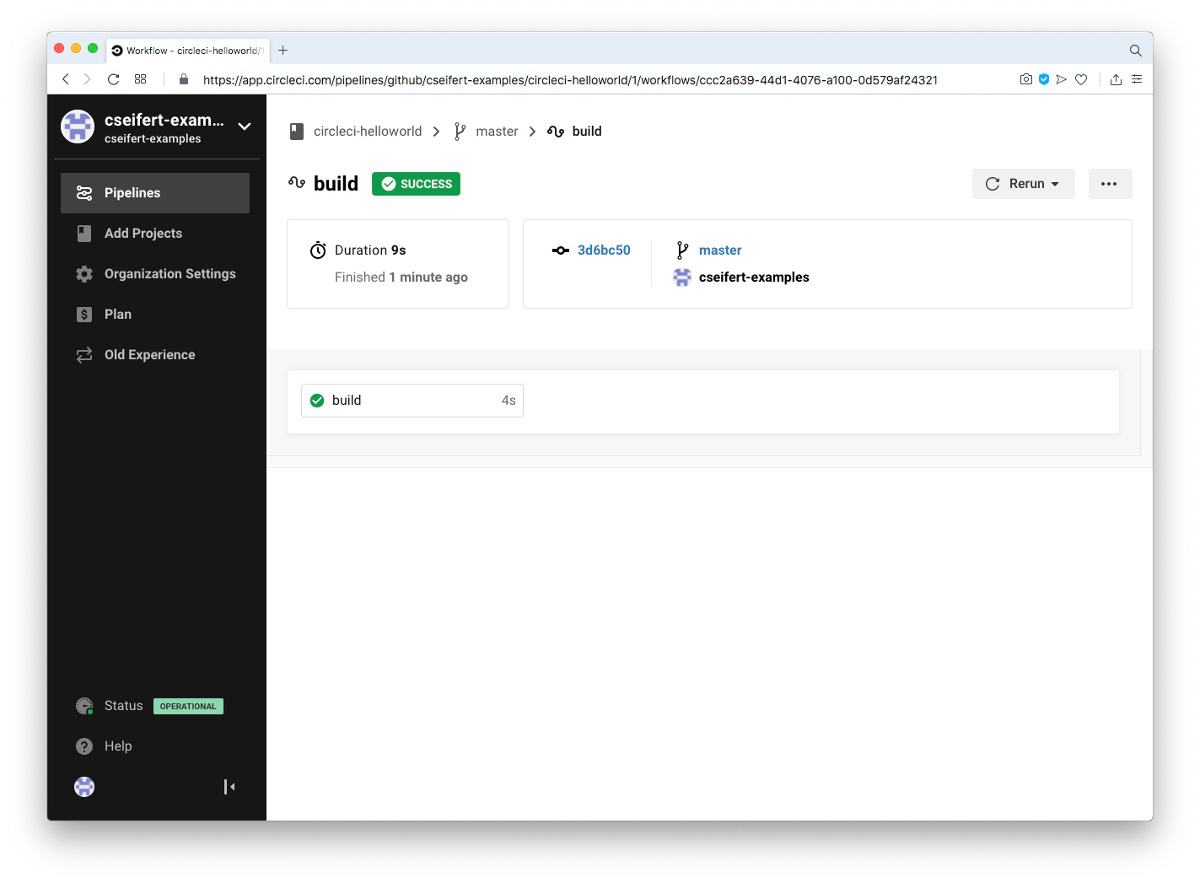
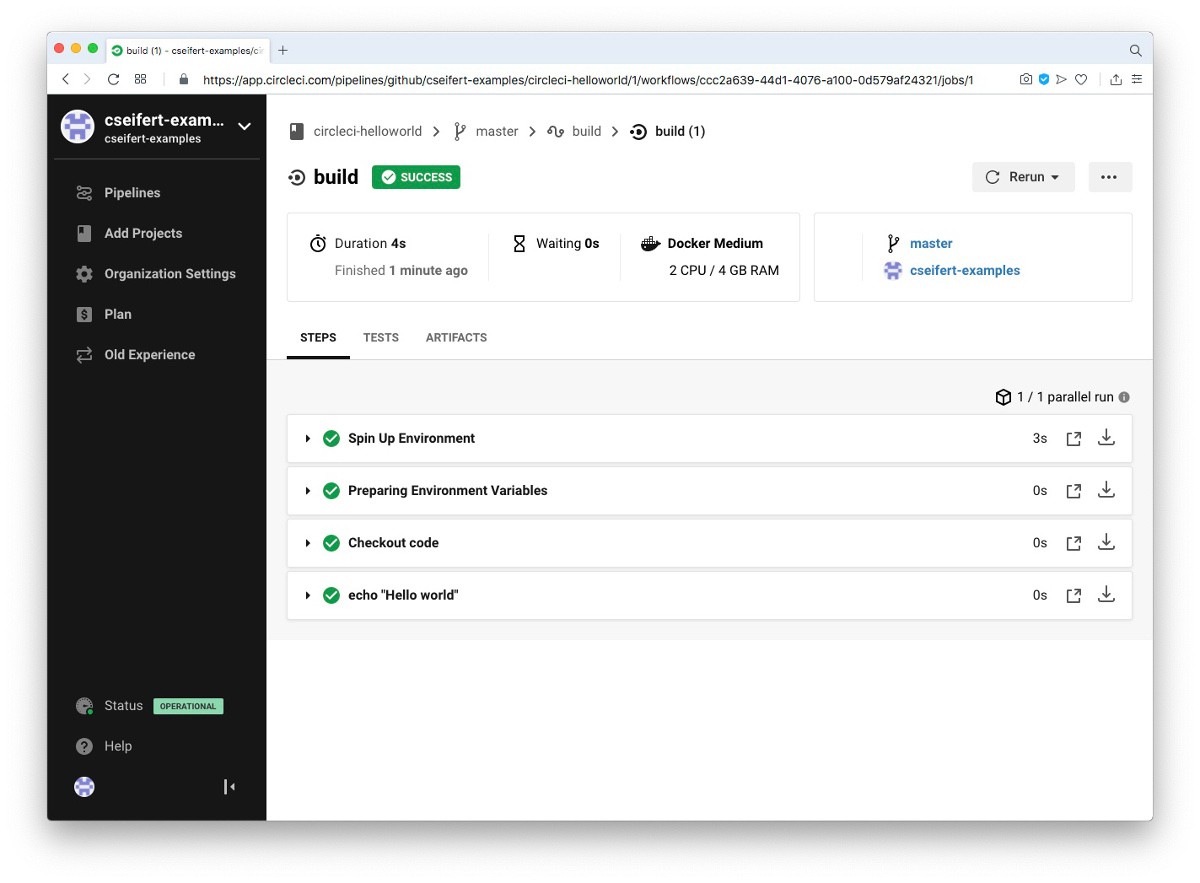
Wir erkennen die Ergebnisse unseres Jobs build sowie der beiden definierten Steps innerhalb des Jobs (unterhalb der beiden von CircleCI selbst initiierten Steps “Spin Up Environment” und “Preparing Environment Variables”).
Reale Konfiguration
Nachdem wir nun gesehen haben, dass eine “Hello world” Konfiguration korrekt von CircleCI verwendet wurde, ist es nun Zeit, unser eigentliches Build-Ziel zu erreichen, nämlich eine Ruby on Rails Anwendung zu bauen.
Integrieren wir unsere Anforderungen 1-4, so ergibt sich folgende Build-Konfiguration:
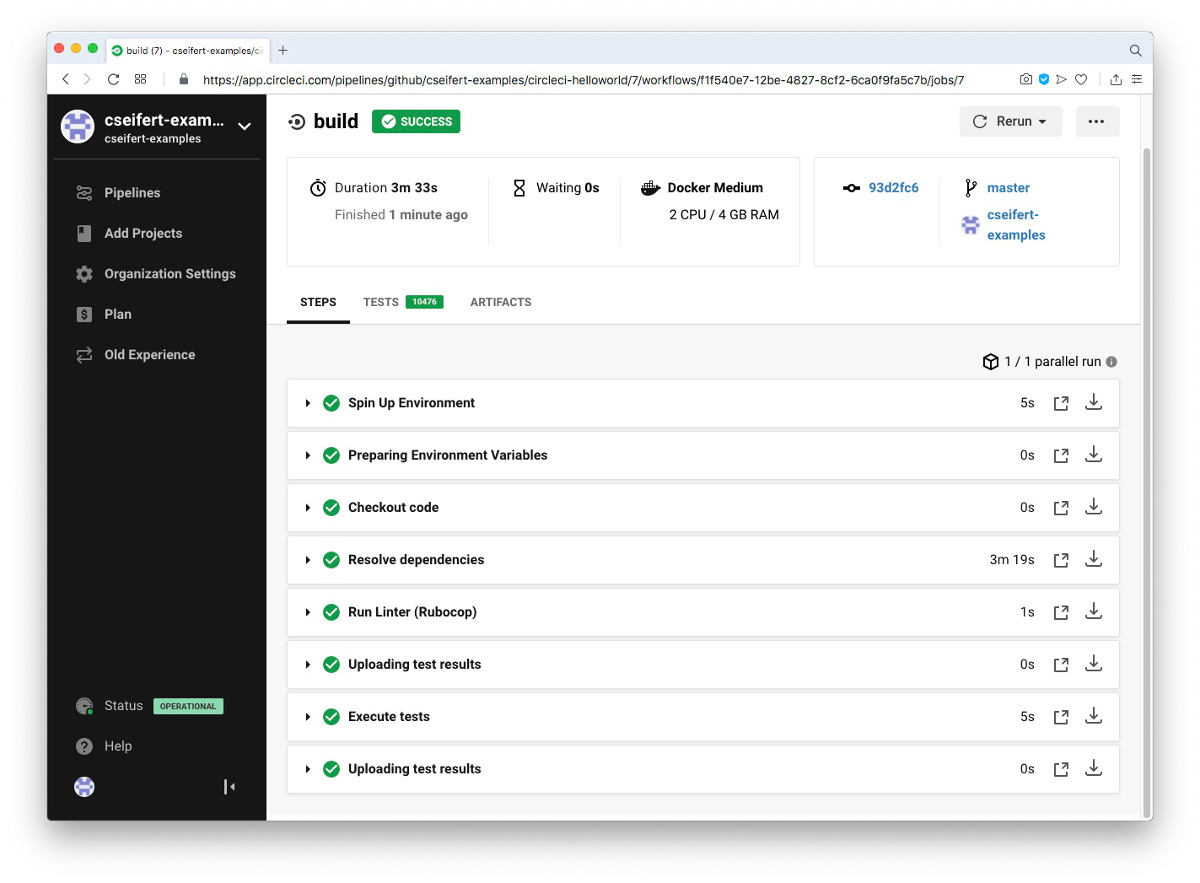
Die beiden Steps store_test_results sind hierbei von besonderem Interesse für eine nahtlose Integration unserer Ergebnisse mit CircleCI. Natürlich könnten wir die Ergebnisse unserer Tests (und potentielle Fehler) direkt aus dem Logfile heraus lesen. CircleCI macht uns aber die Arbeit hier noch einfacher: Alle Ergebnisse, die im JUnit XML Format vorliegen, werden über die store_test_results Steps ausgelesen, ausgewertet und im “Tests” Tab aufgeführt. So werden einzelne Fehler prominent platziert angezeigt.
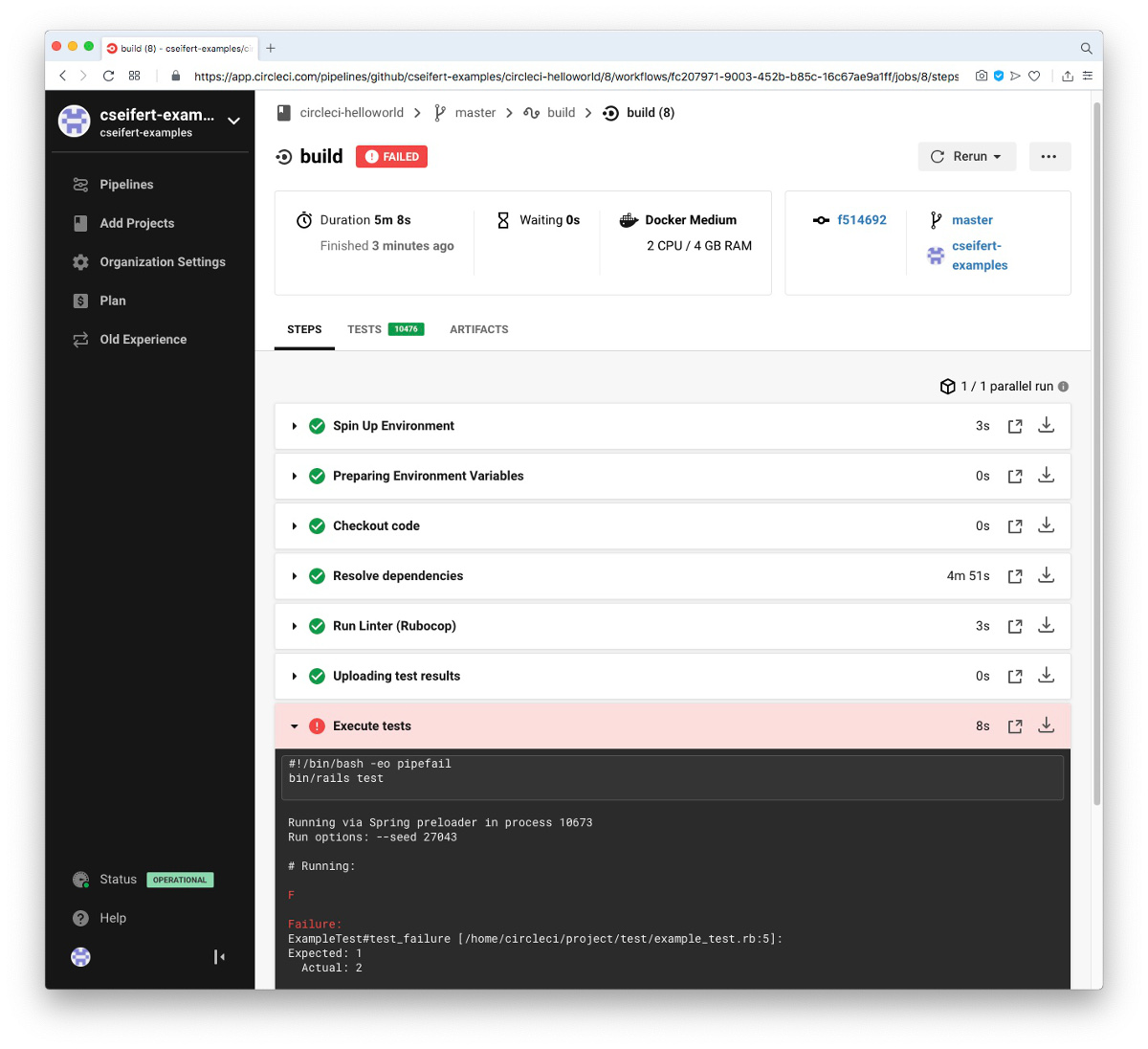
Sehen wir uns einmal an, wie ein fehlerhafter Build aussieht, in dem wir bewusst einen Fehler in unsere Tests einbauen. Starten wir den Build daraufhin erneut, sehen wir nun (wie erwartet) keinen grünen Build, sondern den fehlgeschlagenen Step “Execute tests”, der damit auch den gesamten Build fehlschlagen ließ:
Caches nutzen
Durch die Tatsache, dass für die Ausführung eines Jobs innerhalb eines Builds ein kompletter neuer Docker Container genutzt wird, werden die Ergebnisse früherer Builds nicht berücksichtigt. In der Regel ist das ein Verhalten, das auch genau so gewünscht ist – stellen wir doch gerade so sicher, dass der Build reproduzierbar ist und nicht durch irgendwelche “Überbleibsel” vorheriger Ausführungen “verunreinigt” wird.
An einer Stelle würden uns die Ergebnisse vorheriger Builds enorm weiterhelfen: Beim Installieren aller Abhängigkeiten unseres Projektes. Diese ändern sich schließlich nicht, da sie aus dem globalen Dependency-Repository (in unserem Falle RubyGems) gezogen werden. In der aktuell Konfiguration passiert dies bei jedem Build erneut und dauert ca. fünf Minuten.
CircleCI erlaubt uns zum Glück, selektiv bestimmte Ergebnisse eines Builds in späteren Builds erneut zu verwenden und in einen später laufenden Docker Container zu mounten. In unserem Beispiel werden die Gems, die als Abhängigkeiten unseres Projektes verwendet werden, in das Verzeichnis „./vendor/bundle“ gespeichert. Wir können also unsere Konfiguration so erweitern, dass eben dieses Verzeichnis nach dem Auflösen und Installieren der Abhängigkeiten in den CircleCI Cache für unseren Build geschrieben und bei zukünftigen Builds wieder verwendet wird:
Wir nutzen hier als Key, unter dem die entsprechenden Daten von CircleCI gespeichert werden, die Checksumme der Datei “Gemfile.lock”. Da sich diese Datei (und damit auch ihre Checksumme) bei einer Änderung der Abhängigkeiten ändert, stellen wir so sicher, dass die gecachten Werte auch tatsächlich nur dann verwendet werden, wenn wir die exakt gleichen Abhängigkeiten aus unserem Projekt heraus referenzieren.
Zu beachten hierbei ist, dass die Caches von CircleCI nur für maximal 15 Tagen aufbewahrt werden. Sie können (und sollten) daher nur für solche Anwendungszwecke verwendet werden, wo es darum geht, den Build-Prozess effizienter zu gestalten und zu optimieren. In unserem Beispiel würde das Nicht-Vorhandensein eines Caches zu keinem Fehler führen, sondern lediglich dazu, dass die Build-Zeit ansteigt, da nun (erneut) alle Abhängigkeiten komplett von ihrer ursprünglichen Quelle gezogen werden müssen.
Mehrere Jobs
Im Build-Job haben wir nun erfolgreich unsere Anwendung gebaut bzw. den Linter ausgeführt und die Unit Tests laufen lassen. Zu einem kompletten Release fehlen aber noch die beiden letzten Anforderungen: Das Bauen eines Docker Images und das Publizieren dieses Images zu DockerHub.
Hierzu erweitern wir unsere CircleCI Konfiguration und fügen einen weiteren Job hinzu:
Im Workflow definieren wir nun, dass nach der erfolgreichen Ausführung des build-Jobs (und nur dann) der publish_container-Job gestartet wird. Über die requires-Definition innerhalb des Workflows legen wir fest, dass die Ausführung des build-Jobs abgewartet werden muss. Würden wir folgende Konfiguration verwenden, so würden beide Jobs parallel starten und parallel laufen:
Da wir aber sicherstellen wollen, dass das Docker Image nur gebaut und verteilt wird, wenn sämtliche Tests erfolgreich durchgelaufen sind, stellen wir über requires die entsprechende Abhängigkeit fest.
Pushen wir nun die Änderungen, die von CircleCI automatisch aufgegriffen werden, so erhalten wir folgende Übersicht des Build-Jobs:
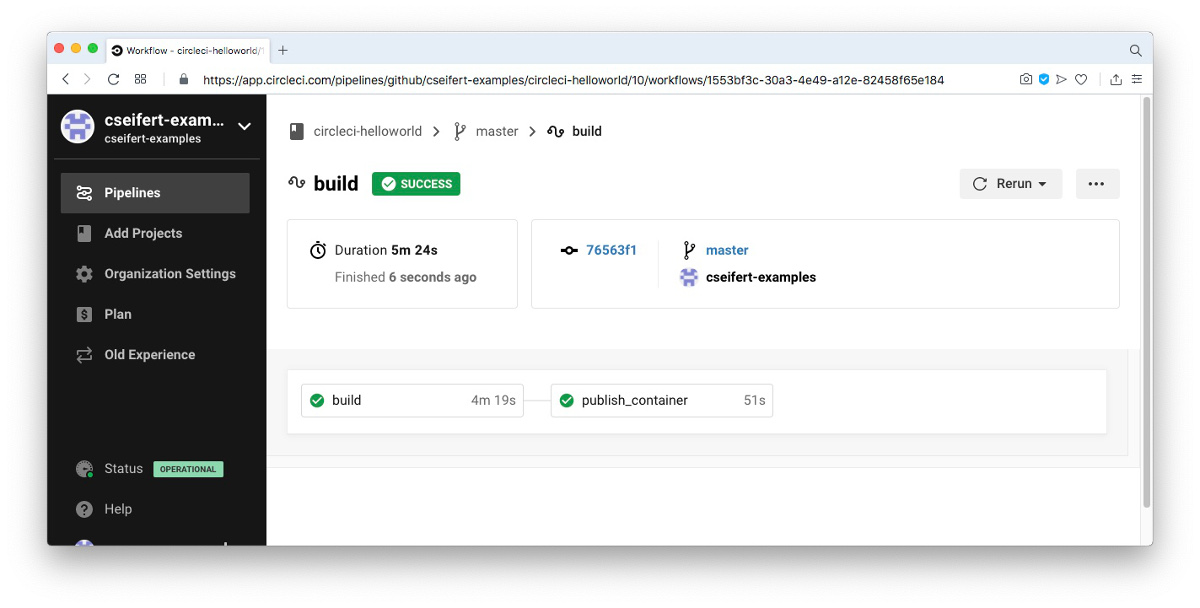
Wir erkennen nun, dass beide Jobs erfolgreich sequentiell durchlaufen wurden.
Passwörter und andere sensitive Daten
Nun fehlt nur noch der finale Schritt: Das Hochladen unseres Docker Images in die DockerHub Registry. Doch bevor ein Update passieren kann, muss ein Login mit den DockerHub Zugangsdaten stattfinden. Diese Zugangsdaten wollen wir natürlich nicht hart kodiert in der CircleCI Konfiguration hinterlegen, sondern diese extern definieren.
CircleCI bietet hierzu die Möglichkeit, über das CircleCI UI für jedes Projekt eine Liste von Umgebungsvariablen zu definieren. Diese Umgebungsvariablen können dann innerhalb eines Jobs (bzw. eines Steps) ausgelesen und verwendet werden. Somit wird eine saubere Trennung zwischen Build-Logik und sensitiven Daten möglich. Konfiguriert werden können die Umgebungsvariablen über den “Environment Variables”-Bereich innerhalb der Konfiguration eines Projektes:
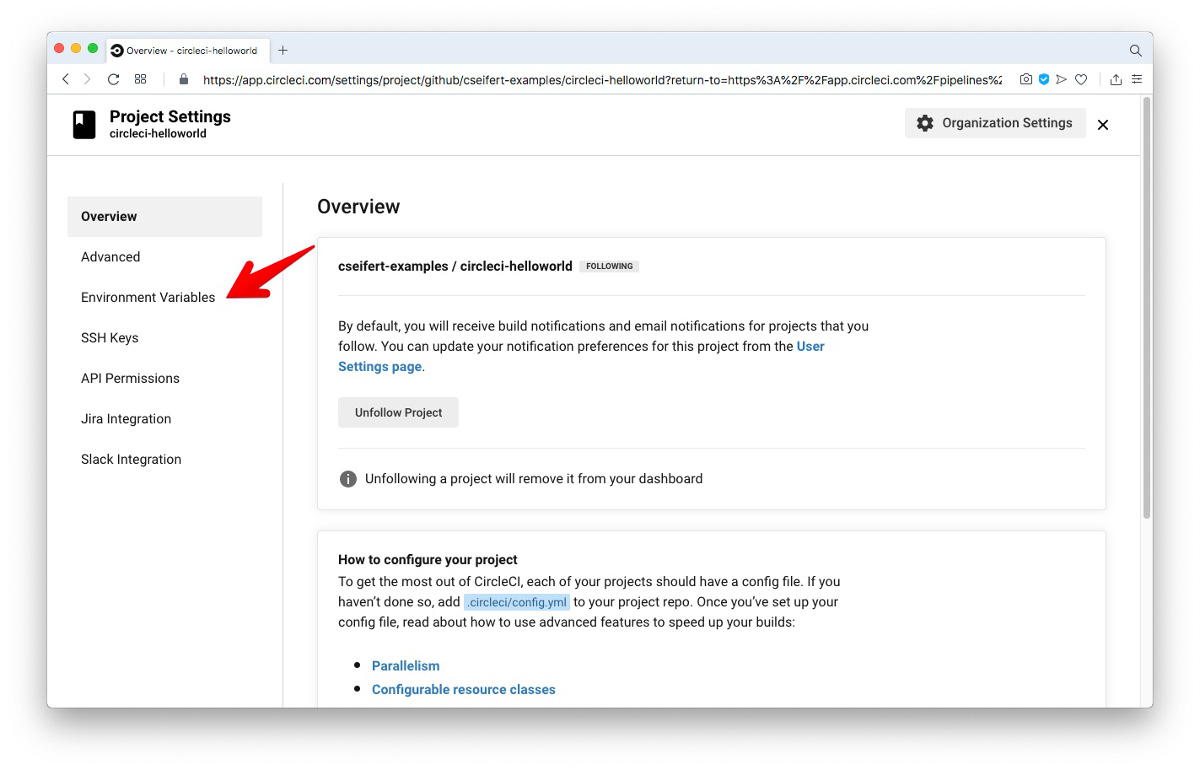
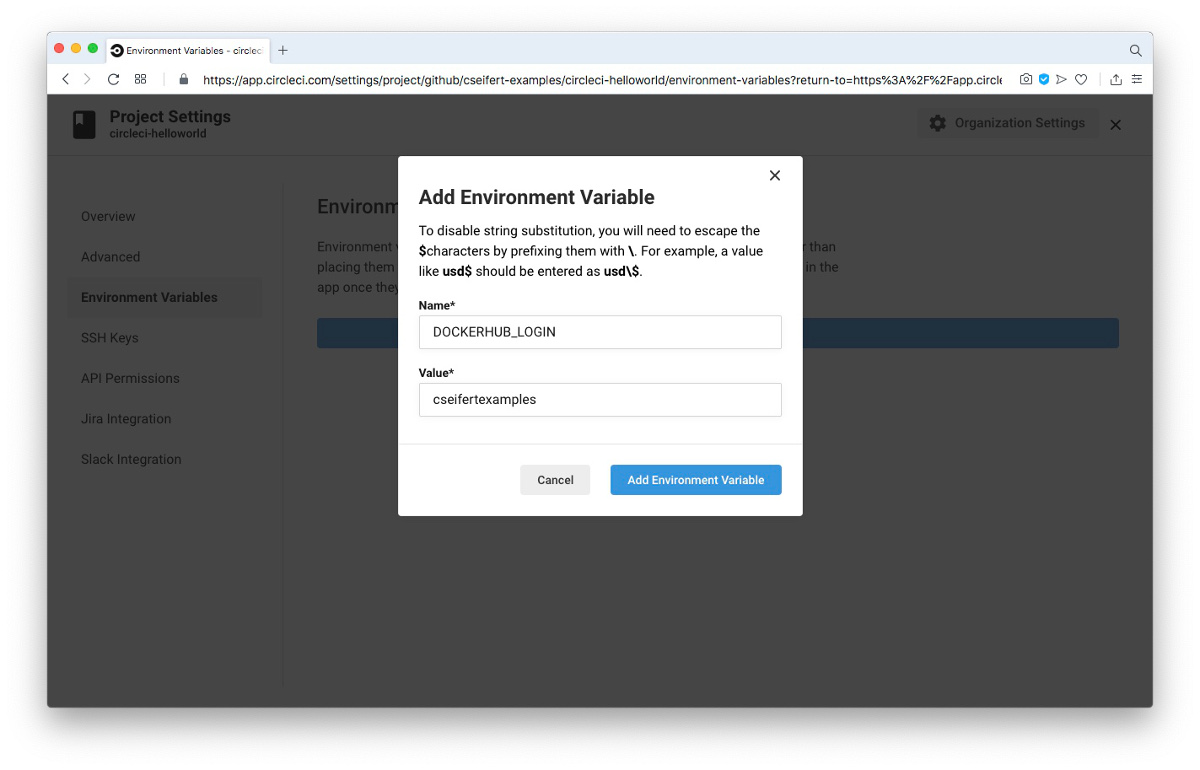
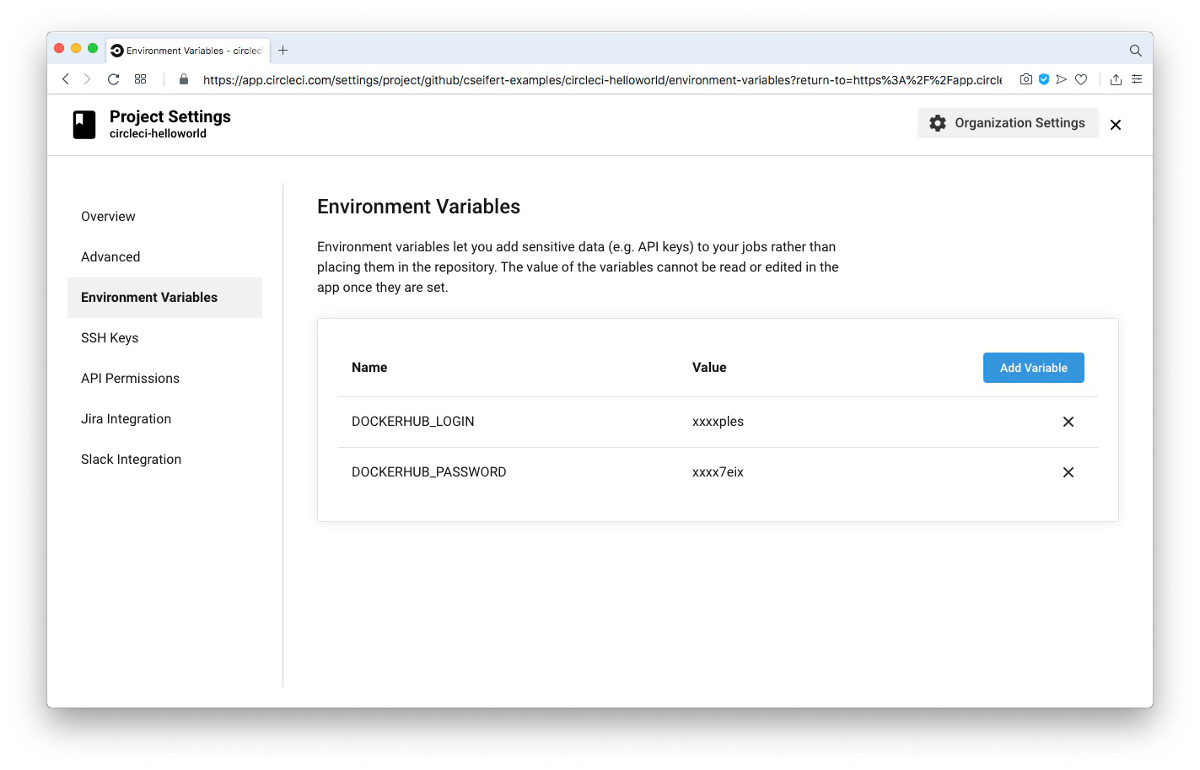
Die beiden so definierten Umgebungsvariablen DOCKERHUB_LOGIN und DOCKERHUB_PASSWORD können wir nun im Build-Script referenzieren:
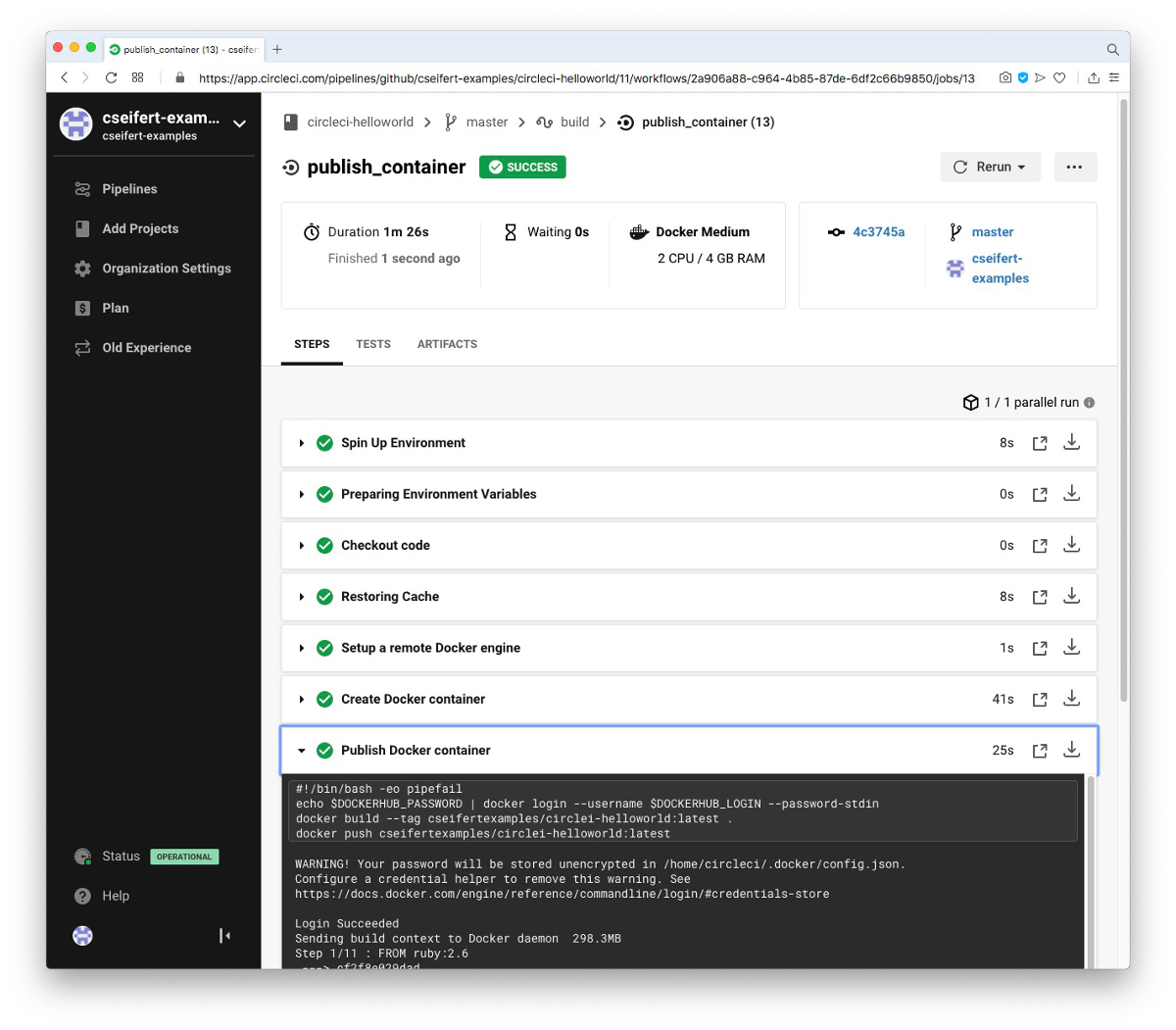
Im Log des Builds erkennen wir jetzt, dass der Login bei DockerHub korrekt durchgeführt und das Image korrekt hochgeladen wurde, ohne dass wir sensitive Daten wie Benutzername und Passwort sehen.
Fazit
Das Aufsetzen einer Continuous Integration Pipeline bei CircleCI ist für typische Anwendungsfälle schnell und einfach erledigt. Die hier gezeigten Beispiele demonstrieren dabei nur die absoluten Basisfunktionalitäten. CircleCI bietet noch deutlich mehr Unterstützung dabei, sowohl Continuous Integration als auch Continuous Deployment zu einem Kinderspiel zu machen. Hat sich man sich einmal an den Funktionsumfang und die Möglichkeiten gewöhnt, so fällt es schwer sich vorzustellen, wie man ohne jemals arbeiten konnte.

Ob beim Schreiben von Code, der Analyse von Anforderungen oder der Ideenfindung mit seinem Team – für ihn geht es nicht nur darum, die "richtige" Lösung zu finden, sondern auch dafür zu sorgen, dass alle Beteiligten den Spaß an ihrer Arbeit behalten.
Ursprünglich von der Technik in der Softwareentwicklung fasziniert, widmet Christian heute einen großen Teil seiner Zeit der Interaktion mit Menschen und setzt sich leidenschaftlich für ein besseres Verständnis zwischen Entwicklungsteams und Business-Stakeholdern ein.
Bei schönem Wetter trifft man Christian häufig auf dem Fahrrad oder beim Joggen im Park. Bei schlechtem Wetter findet man ihn eher auf der Couch, wo er vergeblich versucht, seinen Netflix-Konsum unter Kontrolle zu halten.
