Eine gute Versionsverwaltung ist nicht nur die Basis für die Arbeit aller Softwareentwickler. Auch die Administratoren und IT-Pros arbeiten wegen der immer wichtiger werdenden Automatisierung verstärkt damit. Dokumentation und Wikis werden ebenfalls versioniert und per Pull-Requests geändert. Eine gute Versionsverwaltung ist also das Herzstück jedes digitalen Produktes.
Deshalb ist es nicht verwunderlich, dass fast alle Unternehmen bereits Git als verteilte Versionsverwaltung im Einsatz haben. Leider erfolgt meist aber die Implementierung völlig ungeplant und ohne die nötigen Richtlinien und Anleitungen. Das ist ein Fehler! Richtig eingesetzt erhöht Git die Produktivität, Teamarbeit und Qualität. Das dem Zufall zu überlassen ist ein großes Risiko.
„Wenn Git nicht geändert hat, wie Ihre Teams zusammenarbeiten, dann setzen Sie es falsch ein!“
Was ist Git?
Git ist eine verteilte Versionsverwaltung, die durch Linus Torvalds – dem Initiator von Linux – im Jahr 2005 ins Leben gerufen wurde. Git stammt aus der britischen Umgangssprache und bedeutet so viel wie „Blödmann“. Linus Torvalds begründet den Namen mit folgendem Zitat:
„Ich bin ein egoistischer Mistkerl, und ich benenne all meine Projekte nach mir. Zuerst ‚Linux‘, jetzt eben ‚Git‘“ („I’m an egotistical bastard, and I name all my projects after myself. First ‚Linux‘, now ‚Git’“).
Git ist eine freie Open Source Software und unter der GPLv2 lizenziert.
Im Gegensatz zu klassischen, zentralen Versionsverwaltungen, wie SVN oder TFVC, werden bei Git Dateien nicht vom Server „aus-“ und nach dem editieren „eingecheckt“. Stattdessen werden die Änderungen in einem lokalen Repository gespeichert und danach mit einem zentralen Server synchronisiert.
Im Open Source Bereich dominiert Git inzwischen alle anderen Versionsverwaltungen. Laut Open Hub verwenden rund 70 Prozent aller dort registrierten Softwareprojekte Git. Damit dominiert Git mit großem Abstand zu dem nächstplatzierten Subversion, das 25 Prozent erreicht.
Das richtige Maß an „Governance“
In den meisten Unternehmen will die Unternehmensführung sich nicht in das „Tooling“ für Entwickler einmischen. Dies ist ein Fehler und führt oft zu einer von zwei extremen Ausprägungen: entweder es entsteht ein bunter Mix von allen möglichen Tools, der kaum zu beherrschen ist, oder die Entwickler sind „überreguliert“ und damit nicht wirklich produktiv. Das richtige Maß an „Governance“ muss die richtige Balance zwischen zwei Kräften finden:
- Flexibilität und Autonomie
- Konsistenz und Ausrichtung
Flexibilität und Autonomie: Agile Teams sollen so viel Freiheit wie möglich haben, um sich zu organisieren. Jedes Produkt und jedes Team ist anders – und damit Teams in einen kontinuierlichen Verbesserungsprozess kommen können, benötigen sie auch die Freiheit etwas zu ändern.
Konsistenz und Ausrichtung: Haben die Teams zu viel Autonomie, dann leidet eine gemeinsame Ausrichtung und eine Austauschbarkeit der Teammitglieder. Es ist dann nur nach langer Einarbeitung möglich, Teams neu zusammenzustellen oder Experten in anderen Teams zur Unterstützung hinzuzuziehen. Wenn jedes Team komplett autark und mit seinem eigen Tooling arbeitet, dann können auch keine Synergieeffekte, wie z.B. gemeinsame Schulungen, genutzt werden.
Um das richtige Maß zu finden, empfiehlt sich folgender Leitsatz:
- So viel Konsistenz wie nötig
- So viel Autonomie wie möglich
Eine minimale Richtlinie (Guideline)
Die Konsistenz erreicht man über eine möglichst minimale Richtlinie (Guideline). Hier ein paar Beispiele, was in dieser Richtlinie enthalten sein könnte:
- Die Wahl des Git-Systems (GitHub, Azure Repos, Git Bucket etc.). Hier empfiehlt es sich, eine einheitliche Plattform zu wählen. Sie kann aber auch aus zwei Systemen bestehen – z.B. GitHub für Open Source und Azure Repos für interne Projekte.
- Der Minimale Branching Workflow. GitFlow ist der bekannteste Workflow. Allerdings ist er als minimale Basis viel zu komplex! Eine gute Wahl ist hier Trunk-Based-Development (TBD): Der Master-Branch wird durch Policies geschützt, und es kann nur aus sogenannten Topic-Branches (z.B. Feature oder Bugfix) über einen Pull-Request in ihn „gemerged“ werden (siehe Abbildung 1: Trunk-Based-Development). Notiz: Branching = Verzweigung / to merge = zusammenführen. Ich verwende hier die englischen Begriffe, da es sich meiner Meinung nach um die internationalen Fachbegriffe handelt. Ein Text, der versucht, diese Begriffe alle zu übersetzen, ist sehr schwer zu lesen und zu verstehen.
- Namenskonventionen: Für die Benennung von Branches sollten einheitliche Namenskonventionen gelten. Ein ewiger, philosophischer Streit unter Entwicklern ist, ob die Ordner für Topic-Branches im Plural (z.B. features/*) oder Singular (z.B. feature/*) benannt werden sollen. Für welche Variante man sich entscheidet ist nicht wichtig – man sollte sie nur in allen Projekten konsistent nennen.
Tipp: In den meisten Git-Systemen lassen sich die Berechtigungen so anpassen, dass die Konventionen automatisch eingehalten werden müssen. - Weitere Ergänzungen für Pull-Requests: Pull-Requests lassen sich noch um vieles Erweitern: CI-Build, Code Analyse, Tests und Code Coverage, Verlinkte Work Items etc. Hier ist wichtig, wirklich nur den kleinsten gemeinsamen Nenner als verpflichtend festzulegen. Die Technik schreitet hier schnell vorwärts, und man will nicht ständig die Guidelines anpassen müssen. Weniger ist hier mehr – und vieles ist besser in der Anleitung für Teams (Guidance) aufgehoben.
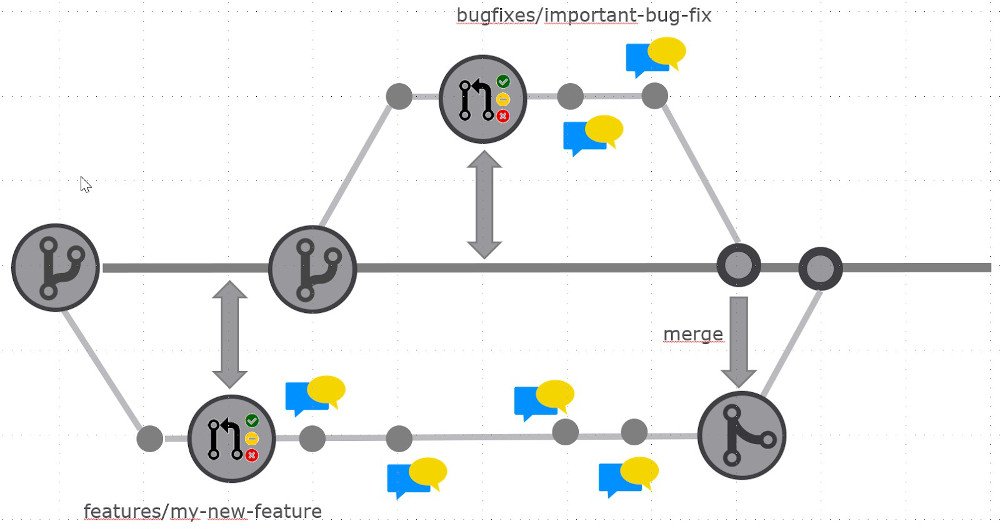
Trunk-Based-Development
Anleitung für Teams (Guidance)
Für alles, was nicht in den Richtlinien festgeschrieben ist, empfiehlt es sich eine Anleitung (Guidance) zu schreiben. Sie hilft den Teams, für die Problemstellungen ihres Alltags die richtigen Entscheidungen zu treffen.
Folgende Punkte sind gut in der Guidance aufgehoben:
- Anzahl, Struktur und Namenskonventionen für Repositories
- Review Guidelines (Review oder Code Review – gegenseitige Durchsicht und Prüfung des Quellcodes)
- Release-Branching / Stabilisierung von Releases mit manuellen Testphasen
- Umgang mit langlebigen Features
- Commit Messages und Pull-Requests
Anzahl, Struktur und Namenskonventionen für Repositories:
Die erste Entscheidung, die ein Team treffen muss, das Git verwendet, ist die Größe und Anzahl der Repositories. Man unterscheidet ein „monolithisches“ Repository (Mono-Repo), ein Repository für die gesamte Anwendung, von einem „Multi-Repo“ – viele einzelne Repositories, die zusammen die Anwendung ergeben. Beide Ansätze haben Vor- und Nachteile. Während der Multi-Repo Ansatz bei einer Microservice-basierten Architektur Vorteile hat, so birgt er doch eine große Komplexität, die oft vorweg nicht gesehen wird. Multi-Repos sind klein und schlank und lassen sich individuell deployen. Leider ist der Umgang mit den Abhängigkeiten und die Fehlersuche eine große Herausforderung. Beim Mono-Repo ist das nicht der Fall. Hier wächst aber das Repository meist recht schnell auf eine beachtliche Größe an. Außerdem muss man für CI-Builds und Releases immer mit Filtern für Dateipfade arbeiten, was die Transparenz und Einfachheit sehr einschränkt.
Auf der grünen Wiese empfehle ich immer, mit einem Mono-Repo zu beginnen. Wenn ein Teil der Lösung dann einen eigenen Lebenszyklus hat, dann kann er in ein eigenes Repository ausgelagert werden. Die wichtigste Faustregel ist dabei, dass der Teil komplett autark ausgerollt werden kann. Dies ist zum Beispiel bei einer versionierten Rest API der Fall. Vorsichtig muss man bei eigenen Nuget- oder NPM-Paketen sein. Sie sind nicht immer ganz so lose gekoppelt, wie man denkt. Man sollte sich immer die Frage stellen, ob man das Paket wirklich komplett autark ausrollen wird, oder ob es in Wirklichkeit immer Teil einer anderen Änderung sein wird.
Beide Varianten haben unterschiedliche Herausforderungen für die Struktur und Namenskonventionen. Bei einem Mono-Repo-Ansatz empfiehlt es sich, schon zu Beginn das Herauslösen von Modulen vorzusehen. Man sollte also unterschiedliche Ordner für Teile der Anwendung wählen und innerhalb von diesen ein eigenes Readme, einen Ordner „src“ und einen Ordner „test“ (siehe Abbildung 2).

Aufbau eines Mono-Repos
Bei der Multi-Repo Variante endet man immer mit einer großen Anzahl an Repositories. Es empfiehlt sich also, eine gute Konvention für den Namen der Repositories zu überlegen. Eine Namenskonvention könnte zum Beispiel so aussehen:
<team>-<app>-<interface/type>-<component/module>
| Variable | Beschreibung |
| Team | Ein Prefix für alle Repositories vom jeweiligen Team. Auf diese Weise bleiben sie lokal zusammen gebündelt. |
| App(likation) | Der Name (Kurzname) der Applikation |
| Optional: Interface/Type | Ggf. kann es Sinn machen, die Anwendung weiter zu unterteilen. Beispielsweise könnten man hier nach Typ (z.B. Packages wie Nuget oder NPM) oder Interface (z.B. REST Service, Messages etc.) unterscheiden, um gleichartige Repositories an einer Stelle zu haben. |
| Komponente/Modul | Der eigentliche Name der Komponente oder des Moduls. |
Da Git auf Linux „case-sensitive“ ist, sollten die Namen immer klein geschrieben werden. Als Trennzeichen hat sich in der Open Source Welt der Bindestrich etabliert, da man den auch in als Link formatierten URLs gut erkennen kann.
Review Guidelines
Der Review-Prozess mit Pull-Requests ist das Herz von Git. An diesem kann man sehen, ob die Zusammenarbeit im Team gut läuft oder nicht. Werden Pull-Requests nur „durchgewunken“ („Kannst du mir bitte mal Pull-Requests XYZ kurz freigeben?“), dann ist das ein Indiz, dass die Zusammenarbeit nicht funktioniert und keine geteilte Verantwortung für den gesamten Code vorhanden ist. Werden nur Formatierung und Kleinigkeiten diskutiert, ist das ebenfalls ein Indiz, dass etwas nicht stimmt. Folgende Tipps sollten die Pull-Requests ihrer Teams zu Leben erwecken:
- Minimale Anzahl: Es sollte ein Minimum von zwei Reviewern geben. Dies erhöht die Qualität der Reviews extrem, da jeder Reviewer weiß, dass auch noch jemand anderes den Code prüft. Dies ist die wichtigste Maßnahme gegen „durchwinken“.
- Geteilte Verantwortung: Die Verantwortung sollte im Team geteilt werden – es sollte also nicht einen Superarchitekt geben, der immer alles prüft. Jedes Teammitglied übernimmt die Review von anderen!
- Code-Of-Conduct: Es sollte einen Code-Of-Conduct geben, in dem geregelt wird, wie man sich bei einer Review verhält. Ein gutes Beispiel ist der Microsoft Open Source Code of Conduct: Sei freundlich und geduldig, sei einladend, sei respektvoll, verstehe Meinungsverschiedenheiten. Ein Code-Of-Conduct löst natürlich allein noch keine Probleme – er hilft aber bei der kontinuierlichen Verbesserung, da man auf ihn verweisen kann.
- Integration in bestehenden Prozess: Wenn Sie z.B. nach Scrum arbeiten, dann sollten Sie die Bewertung und Verbesserung des Review-Prozesse in Scrum integrieren. Das heißt, am Ende jeden Sprints sollten sich die Teammitglieder gegenseitig Feedback zu den Reviews geben und danach dann die Review-Praxis anpassen.
- Mehr ist mehr: Lieber zu viele Reviewer als zu wenige. Besonders bei Spezialthemen (User Interface / Corporate Identity, Security, Infrastruktur etc.). Sind solche Dinge von der Änderung betroffen, dann sollten die entsprechenden Experten – auch wenn sie nicht Teil des Teams sind – als Reviewer hinzugezogen werden. Die meisten Git-Systeme haben eine Funktion, das zu automatisieren (Code Owners in GitHub, Automatic Reviewers in Azure Repos).
Release-Branching / Stabilisierung von Releases mit manuellen Testphasen
Durchlaufen Releases längere Stabilisierungsphasen oder werden unterschiedliche Releases für Umgebungen oder Plattformen benötigt, dann können dafür Release-Branches erstellt werden. Meine Empfehlung ist, sich bei Release-Branches nicht auf Tags zu verlassen. Zu schnell werden diese vergessen. Außerdem sollten Release-Branches One-Way (Einbahnstraßen) sein und nie wieder zurück gemerged werden.
Sollen Bugfixes oder andere Änderungen nötig sein, dann kann man diese per Cherry-Picking in einen neuen Feature-Branch übertragen und dann per Pull-Request mergen (siehe Abbildung 3). Je nach Arbeitsweise kann es hier auch Sinn machen, die Änderungen im Master-Branch vorzunehmen und dann in den Release-Branch zu übertragen – auf diese Weise würde sichergestellt, dass alle Änderungen im Master-Branch vorhanden sind. Für kunden- oder plattformspezifische Anpassungen macht dieser Workflow natürlich keinen Sinn. In diesem Fall würde man wichtige Bugfixes nach Master übertragen und den Rest lokal im Release-Branch ändern. Wichtig ist, dass aber auf jeden Fall der Release Branch nie wieder direkt zurück nach Master integriert wird. In kleinen Teams und mit neuen Produkten mögen Ihnen diese Sicherheitsvorkehrungen übertrieben vorkommen – aber ich bin der Meinung, es ist besser, mit einem Prozess zu beginnen, der auch für große Teams funktioniert. Meistens merkt man nicht, wann man die Grenze überschritten hat, bei der man die Komplexität noch im Griff hat.
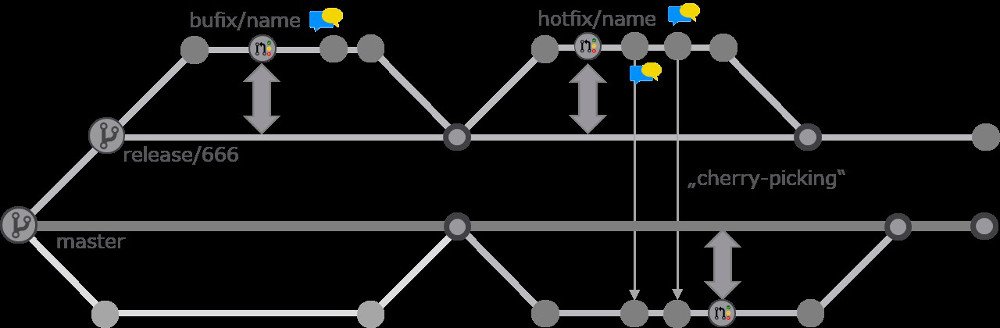
Cherry-Picking Bugfixes aus einem Release-Branch nach Master
Umgang mit langlebigen Features
Bei den Topic-Branches (z.B. Feature-Branches) sagt man immer, sie sollen „kurzlebig“ sein. Das bezieht sich aber nicht unbedingt nur auf die Dauer – sondern wichtiger noch auf die Komplexität. Solange in einem Feature-Branch die Änderungen immer per Rebase auf dem Master-Branch (origin/master) „abgespielt“ werden können, so lange kann der Branch ruhig auf z.B. eine Architekturentscheidung oder ein Feature in einem anderen Projekt warten. Die Topic-Branches sollten aber von der Komplexität nicht zu groß werden. Wie aber geht man mit komplexen Features, wie z.B. einem Redesign oder einem komplett neuen Modul um?
Es gibt zwei Varianten dies zu tun: die klassische Praxis sind langlebige Branches, die regelmäßig vorwärts und rückwärts integriert werden. Diese Variante skaliert nur sehr schlecht. Ein langlebiger Branch, der parallel zu Master existiert, ist wie ein Kredit: je länger er läuft, desto größer wird die Schuld. Langlebige Branches sind technische Schulden, die irgendwann – durch aufwändiges Mergen – getilgt werden müssen.
Die bessere Variante sind Feature-Flags bzw. Feature-Toggles. Für den einfachen Fall von langlebigen Features reicht erst mal ein einfaches If-Statement auf Basis einer Konfigurationsvariable (siehe Abbildung 4).

Die einfachste Form eines Feature-Flags
Feature-Flags benötigen ein Umdenken bei Entwicklern. Es ist nicht so einfach, sie dazu zu bringen, sie zu nutzen. Einmal implementiert, wollen sie aber nie wieder zurück. Hat man Feature-Flags erst mal im Einsatz, dann kann man viele Dinge tun, die man mit Feature-Branches nicht tun kann: A/B-Testing, Testing in Production, Feature Lifecycle (Opt-In, Opt-Out) u.v.m. Außerdem funktioniert diese Variante auch in sehr komplexen Umgebungen mit sehr vielen Entwicklern.
Feature-Flags haben auch ihre Herausforderungen – trotzdem sollten sie auf jeden Fall Teil der Guidance sein. Richtig eingesetzt kann man sehr viel Komplexität reduzieren – und viel an Geschwindigkeit gewinnen.
Commit-Messages und Pull-Requests
Für Commit-Messages und Pull-Requests gilt das Single-Responsibility-Prinzip (SRP, auf deutsch „Prinzip der eindeutigen Verantwortlichkeit“). Jeder Commit sollte klein und fokussiert sein und genau einen Zweck habe. Besonders Refaktorisierungen und größere Umbauaktionen sollten nicht mit anderen Änderungen vermischt werden. Ansonsten ist die Review in einem Pull-Request schwierig.
Bei Commit-Messages sollte das Team auch einen Standard wählen. Sollen Commit-Messages im Präsens oder in der Vergangenheit geschrieben werden? Sollen Sie mit einem Punkt enden? Dies sind durchaus auch Entscheidungen, die man in die Richtlinien mit aufnehmen kann. Haben sich Entwickler erst einmal an eine Art gewöhnt, dann fällt es schwer, sich wieder umzugewöhnen. Auf jeden Fall sollte sich aber das Team auf eine Variante festlegen.
Dasselbe wie für die Commit-Messages gilt auch für die Pull-Requests. Jeder Pull-Request sollte genau einen Zweck haben. Er sollte eine gute Beschreibung haben, die den Reviewer schnell in den Kontext der aktuellen Problemstellung einführt. Außerdem sollte jeder Pull-Request individuell deployed und getestet werden können.
Commit-Messages und Pull-Requests sind Teil der Team-Kultur. Wie die Teams damit umgehen, entwickelt sich ständig weiter. Trotzdem kann man den Teams einen guten Start geben, indem man ihnen zu Beginn eine gute Anleitung an die Hand gibt.
Merge-Strategien
Um Pull-Requests zu mergen, gibt es je nach Git-System unterschiedliche Strategien. Welche Strategie Sinn macht, kommt sehr auf die Arbeitsweise des Teams an – deshalb sollte man auch nicht für das ganze Unternehmen festlegen. Im Großen und Ganzen gibt es zwei Strategien:
No-Fast-Forward Merge (–no-ff)
Der Standard in den meisten Systemen ist der No-Fast-Forward Merge. Bei ihm bleiben die einzelnen Commits genauso erhalten, wie sie gemacht wurden. Die Commits werden dabei als separater Pfad dargestellt (siehe Abbildung 5). Der No-Fast-Forward Merge ist damit die richtige Wahl für alle Teams, die sehr gute Commit-Messages schreiben und diese im Master sehen wollen.
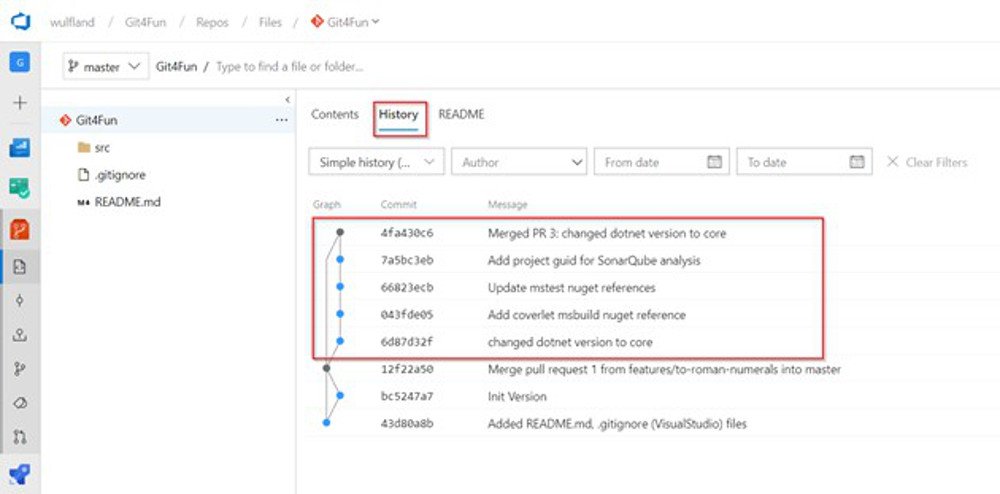
No-Fast-Forward Merge
Squash Merge (–squash)
Beim Squash Merge werden alle Änderungen als ein einzelner Commit zusammengefasst (siehe Abbildung 6). Diese Strategie ist besonders für Teams geeignet, die sehr intensiv mit den Pull-Requests arbeiten und weniger Zeit und Aufwand in einzelne Commits investieren. Der Squash Merge sorgt für einen sehr aufgeräumten Master Branch.
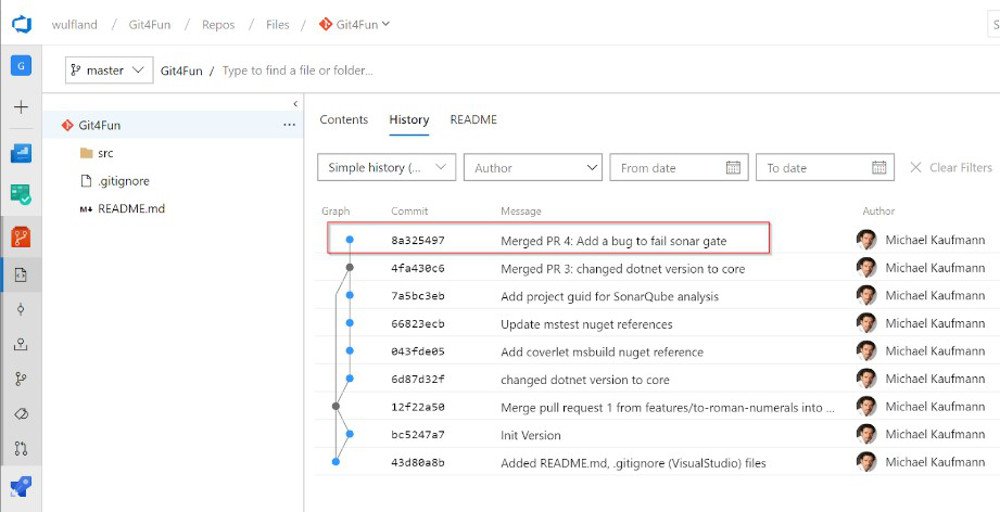
Squash-Merge
Rebase and Merge / Semi-Linear-Merge
Neben den zwei Hauptstrategien haben einige Systeme noch etwas exotischere Varianten. Zum Beispiel gibt es den Rebase and Merge – dabei wird erst ein Rebase auf Master gemacht und dann die Änderungen per Cherry-Picking direkt auf Master abgespielt. Bei Semi-Linear-Merge wird ebenfalls erst ein Rebase gemacht – danach werden aber die Änderungen per No-Fast-Forward Merge gemerged und tauchen in der Zeitachse als separater Zweig auf.
Für welche der Methoden sich ein Team entscheiden sollte, hängt sehr von seiner Arbeitsweise ab. Wichtig ist, dass die einzelnen Methoden nicht ständig gemischt werden. Das Team sollte sich auf eine Variante einigen und diese dann konstant anwenden.
Training
Wenn Sie jetzt die Richtlinien (Guidelines) und die Anleitungen (Guidance) für Ihre Teams erstellt haben, dann sollten Sie noch ein Training konzipieren, um dieses Wissen in Ihre Teams zu transportieren. Das Training sollte auch die Grundkonzepte von Git, den Umgang mit der Konsole,dem Editor und Git-Aliase enthalten. Ein solches Training dauert nicht länger als einen Tag und ist sowohl für Administratoren als auch für Entwickler ein guter „Jump-Start“ in das Arbeiten mit der verteilten Versionsverwaltung Git. Bei uns ist das Training Teil einer Onboarding-Schulung, die auch jeder neue Entwickler – unabhängig von seinem Erfahrungs-Level – durchlaufen muss.
Git Implementation – Fazit
Git kann die Zusammenarbeit, sowohl in ihren Teams als auch teamübergreifend, komplett verändern. Deshalb sollten Sie die Einführung nicht dem Zufall überlassen! Schaffen Sie mit dem richtigen Maß an Richtlinien, Anleitungen und Schulungen eine erfolgreiche Einführung. Auch wenn Teile Ihrer Firma bereits Git nutzen – von einer strategischen Einführung im Unternehmen profitieren letztendlich alle.

- Schneller, besser, kollaborativer: Git richtig implementieren - 12. November 2019
