Wenn man sich überlegt, ein Projekt mit KI umzusetzen, stellen sich zwei Fragen: Erstens, ist es überhaupt möglich und sinnvoll, KI für den jeweiligen Zweck einzusetzen? Und zweitens: Für welches Modell mit welchen Einstellungen soll man sich entscheiden?
Hilfe bei der zweiten Frage bieten die GitHub Models, mit denen Sie verschiedene KI-Sprachmodelle direkt im Browser ausprobieren und herausfinden können, welches sich am besten für Ihre Anwendung eignet.
Denn angesichts der vielen Modelle und Einstellungsmöglichkeiten kann man sich leicht überfordert fühlen. Da sind zuerst einmal die verschiedenen Hersteller: von Meta über DeepSeek bis hin zu OpenAI und Mistral. Und jede dieser Firmen hat noch unterschiedliche Modelle im Angebot. Von Mistral gibt es im Herbst 2025 beispielsweise Mistral Medium, Mistral Nemo, Ministral 3B, Mistral Small 3.1, Mistral Large 24.11 und Codestral 25.01. Die Modelle unterscheiden sich in ihren Fähigkeiten, aber auch im Preis. Für ein optimales Ergebnis ist es dann noch wichtig, beim gewählten Modell an den richtigen Schrauben für die Anpassungen zu drehen, also die richtigen Parameter zu wählen.
Man muss also erst einmal eine Menge herumprobieren, um das richtige Modell mit den passenden Einstellungen zu finden. Die meisten Hersteller bieten Playgrounds, auf denen Sie die Modelle testen können. Dafür muss man sich allerdings bei den einzelnen Herstellern registrieren und sich in der jeweiligen Oberfläche zurechtfinden … das ist natürlich machbar, aber umständlich (und auch mühsam).
Genau hier setzen die GitHub Models an. Die verschiedenen Modelle der Hersteller lassen sich ohne Umwege über eine einheitliche Oberfläche ausprobieren – Sie benötigen dafür nur einen GitHub-Account. Besonders praktisch: Die Modelle können Sie direkt gegenüberstellen: Sie haben die Möglichkeit, denselben Prompt mit identischen Parametern an verschiedene Modelle zu senden und die Ergebnisse zu analysieren. Alternativ lässt sich ein Modell auch mit sich selbst, aber mit unterschiedlichen Parametern vergleichen.
Modelle nach Kriterien suchen
Und so nutzen Sie GitHub Models: Falls Sie noch keinen GitHub-Account haben, können Sie sich einen kostenlos unter https://github.com/signup anlegen.
Rufen Sie dann die Webseite https://github.com/marketplace?type=models auf. Hier erscheinen die zuletzt hinzugefügten Modelle oder wahlweise die populärsten drei. Darunter werden alle verfügbaren Modelle aufgelistet. Da die Liste sehr lang ist, empfiehlt es sich, einen Filter zu nutzen. Sie können nach folgenden Kriterien filtern:
- Hersteller (Publisher)
- Fähigkeiten (Capability): Hier wird zwischen Chat/completion und Embeddings unterschieden.
Chat/completion braucht man für die Textproduktion, also wenn es um die Beantwortung von Fragen oder um Dialoge geht.
Embeddings sind Vektordarstellungen von Daten in einem kontinuierlichen Zahlenraum. Je näher zwei Wörter in ihrer Bedeutung sind, desto näher sind auch ihre Vektoren. Embeddings benötigen Sie, um Rohdaten für ein Modell vorzubereiten. Genutzt werden Embeddings für Empfehlungssysteme oder RAG (Retrieval-Augmented Generation), wenn Daten aus einer Wissensdatenbank geholt werden sollen.
- Kategorien (Category) beziehen sich auf den Zweck der Verwendung: Zur Auswahl stehen unter anderem Agents, Audio, Coding, Reasoning und Vision.
Außerdem können Sie die Modelle sortieren und sich die zuletzt hinzugefügten, also die neuesten, zuerst anzeigen lassen.
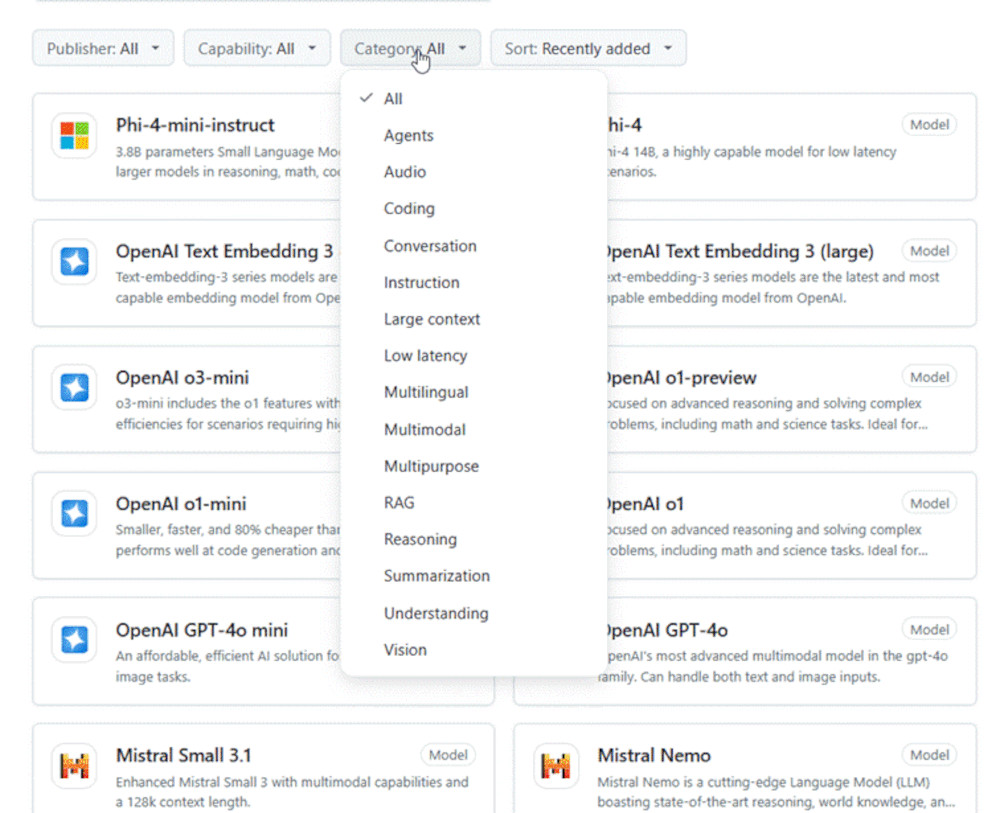
Modelle filtern und sortieren
Ein Klick auf ein Modell wählt es aus und zeigt weitere Informationen:
- Readme liefert eine Beschreibung der Features des Modells.
- Evaluation bietet weitere Details und vergleicht das gewählte Modell mit anderen.
- Transparency listet auf, für welche Anwendungsfälle (Intended Use) das Modell geeignet ist.
- License bietet einen Link zur Lizenz.

Finden Sie jetzt Ihre Wunsch-Domain.
-
Große Auswahl an günstigen Domain-Endungen.
Keine verdeckte Kosten.
Im rechten Bereich werden wichtige Features zusammengefasst, wie das Kontextfenster, d.h. die Gesamtmenge an Text, die ein Sprachmodell bei der Erzeugung von Texten berücksichtigen kann, der Stand der Trainingsdaten (Datum), die Ebene für die kostenlose Nutzung wie beispielsweise Low (dazu später mehr), die Kosten und welcher Provider das unterstützt. Tags zeigen mögliche Einsatzbereiche, und außerdem sehen Sie, welche natürlichen Sprachen unterstützt werden.
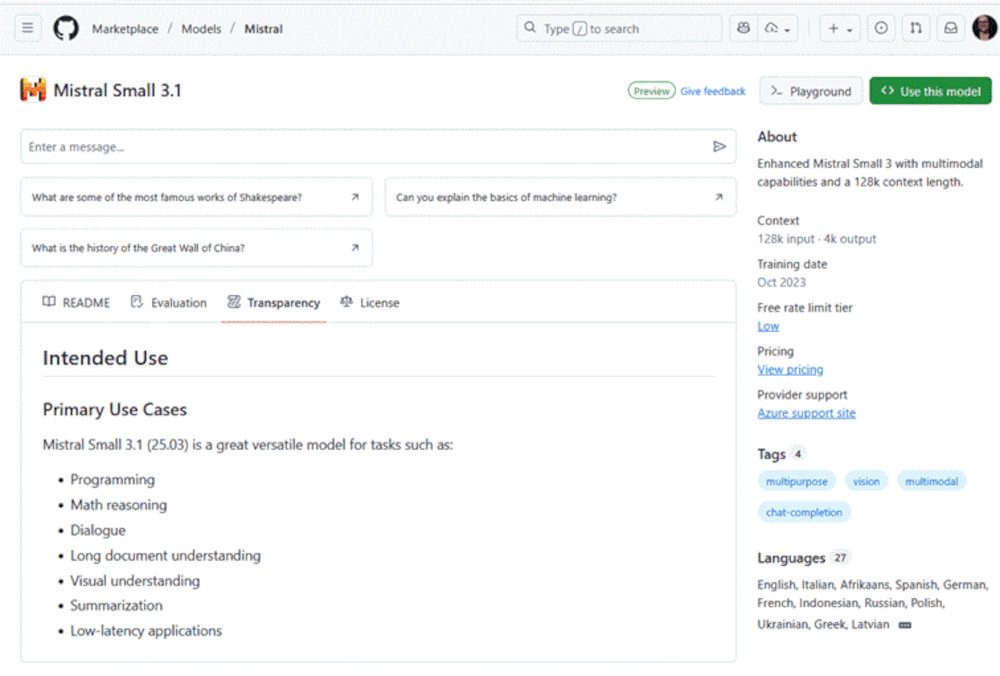
Details über das Modell – hier Mistral Small
Ausprobieren
Nun können Sie direkt das Modell ausprobieren, indem Sie einen der vorgeschlagenen Prompts wählen oder in das Textfeld (Enter a message) einen eigenen eingeben. Mehr Möglichkeiten bietet der Button Playground rechts oben.
Auf der neuen Seite sehen Sie direkt unten ein großes Feld für Ihren Prompt. Im Bildschirmbereich darüber stehen Beispielprompts, die Sie ausführen können. Außerdem werden in diesem Fenster auch die Ergebnisse angezeigt.
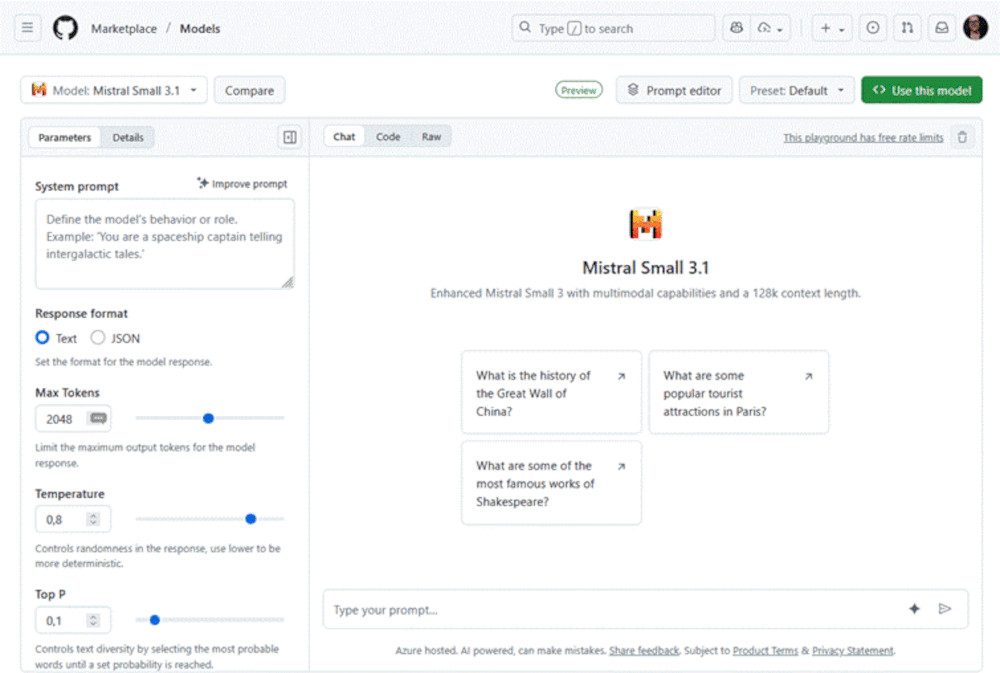
Der Playground
Über den linken Bereich steuern Sie nach Klick auf Parameters das Verhalten des Modells genauer:
- Der Systemprompt legt das allgemeine Verhalten des Modells fest.
- Außerdem können Sie als Format der Antwort zwischen Text und JSON wählen.
- Max Tokens regelt, wie viele Tokens bei der Antwort maximal verwendet werden.
Tokens werden von Modellen bei der Analyse/Zerlegung von Inhalten benutzt. Ein Token ist meist etwas kürzer als ein Wort. So besteht der Satz „Ich trinke morgens grünen Tee“ beim OpenAI-Modell GPT-4o aus acht Tokens. Dabei werden „trinke“ und „grünen“ jeweils in die zwei Tokens tr-inke und grü-nen zerlegt, und das Satzzeichen (Punkt) ist ebenfalls ein eigenes Token.
Die Aufteilung in Tokens ist modellabhängig, beispielsweise werden für denselben Satz bei GPT-3.5 elf Tokens ermittelt. Übrigens können Sie die Zerlegung in Tokens bei OpenAI-Modellen im Tokenizer ausprobieren. Tokens sind in der Praxis relevant, da die Kosten für die Verwendung von Modellen üblicherweise über die Anzahl der benutzten Tokens ermittelt werden.
- Die Temperatur legt fest, wie „zufällig“ die Antwort sein soll. Je niedriger der Wert, desto deterministischer die Antwort, je höher, desto zufälliger/kreativer. Wenn das Modell brainstormen oder „kreativ“ sein soll, ist ein höherer Wert sinnvoll, bei sachlich-präzisen Aufgaben ein niedrigerer.
- Top P kontrolliert die Vielfalt der Antworten.
Temperatur und Top P beeinflussen beide die Zufälligkeit der Texterzeugung, aber es gibt Unterschiede. Die Temperatur verändert die Wahrscheinlichkeitsverteilung aller möglichen nächsten Tokens, wohingegen Top P bestimmt, welche Teilmenge der wahrscheinlichsten Tokens überhaupt berücksichtigt werden soll.
- Stop: Der Output wird abgeschnitten, sobald eine der angegebenen Stop-Sequenzen erscheint.
Es gibt also mehrere Möglichkeiten, das Verhalten der Modelle einzustellen – es empfiehlt sich allerdings, bei den ersten Versuchen alle Parameter auf dem Standard zu belassen und danach gezielt bei einzelnen Parametern Anpassungen durchzuführen.
Oberhalb des großen Bereichs stehen drei Tabs, über die Sie angeben, wie Sie die Interaktion sehen wollen: Chat, Code und Raw.
Chat ist eine Chatfunktion, so wie Sie sie von ChatGPT kennen. Wenn Sie mit einem Gespräch begonnen haben, ist das Papierkorb-Icon Reset chat history rechts oben wichtig. Damit können Sie nämlich die aktuelle Konversation löschen. Haben Sie beispielsweise dem Modell Ihren Namen mitgeteilt, so merkt sich das Modell den Namen, weil die vorherigen Antworten immer wieder bei der Konversation mitgeschickt werden. Wenn Sie hingegen den Papierkorb-Button drücken, beginnt das Gespräch von vorne und das Modell kennt Ihren Namen nicht mehr.
Beispielcode ansehen
Bei Code sehen Sie den Code, den Sie nutzen können. Im Auswahlmenü entscheiden Sie sich für die Sprache, die verwendet werden soll. Möglich sind Python, JavaScript, Java, C#, Java oder REST, wobei es sich bei REST natürlich nicht um eine Sprache, sondern um den Schnittstellen-Aufruf (API-Request) handelt.
Im Auswahlmenü rechts daneben legen Sie die benutzte API fest. Sie können ein Modell über das eigene SDK des Modells verwenden – bei Mistral etwa Mistral AI SDK – oder über Azure AI, das eine einheitliche Plattform für verschiedene Modelle bietet. Azure AI ist ein KI-Dienst von Microsoft, und ihn zu nutzen kann praktisch sein, wenn Sie von einem Modell eines Herstellers zu einem Modell eines anderen Herstellers wechseln wollen. Dann müssen Sie nur den Modellnamen ändern, sich aber nicht mit den Feinheiten der jeweiligen SDKs auseinandersetzen.
Wenn Sie links Parameter ändern, wird diese Änderung direkt in den Code übernommen. Den Code können Sie dann direkt kopieren und nutzen. Damit das klappt, brauchen Sie allerdings ein GitHub-Token. Der Anfang des Codes sieht bei Python wie folgt aus (das Grundprinzip ist bei allen Sprachen gleich):
import os
from mistralai import Mistral, UserMessage, SystemMessage
token = os.environ["GITHUB_TOKEN"]
endpoint = "https://models.github.ai/inference"
model = "mistral-ai/mistral-small-2503"
Die benötigten Bibliotheken werden importiert, außerdem wird der Endpoint festgelegt – also die URL, an die die Anfrage gesendet werden soll – und das Modell angegeben. Zusätzlich muss noch ein GITHUB_TOKEN mitgesendet werden, worüber Sie sich authentifizieren. Ein Personal Access Token ist ein individueller Zugriffsschlüssel, den man im GitHub-Konto erstellt und der es ermöglicht, sicher auf die API zuzugreifen. Die Modelle können Sie kostenlos austesten, dabei aber nicht unbegrenzt viele Anfragen senden. Deswegen ist eine Authentifizierung notwendig, wenn Sie den Code verwenden.
Weitere Infos zu den GitHub-Tokens lesen Sie unter “Verwalten deiner persönlichen Zugriffstoken” in der Dokumentation.
Detailliertere Informationen zur Verwendung des Codes finden Sie über den Button Use this model, dazu auch gleich etwas mehr.
Schließlich gibt es neben dem Tab Chat und Code auch noch Raw, wo Sie sehen, welche Nachrichten hin und her gesendet werden.
Vergleichen
Besonders interessant ist die Möglichkeit, verschiedene Modelle zu vergleichen. Den Compare-Button finden Sie neben dem Namen des gerade gewählten Modells.
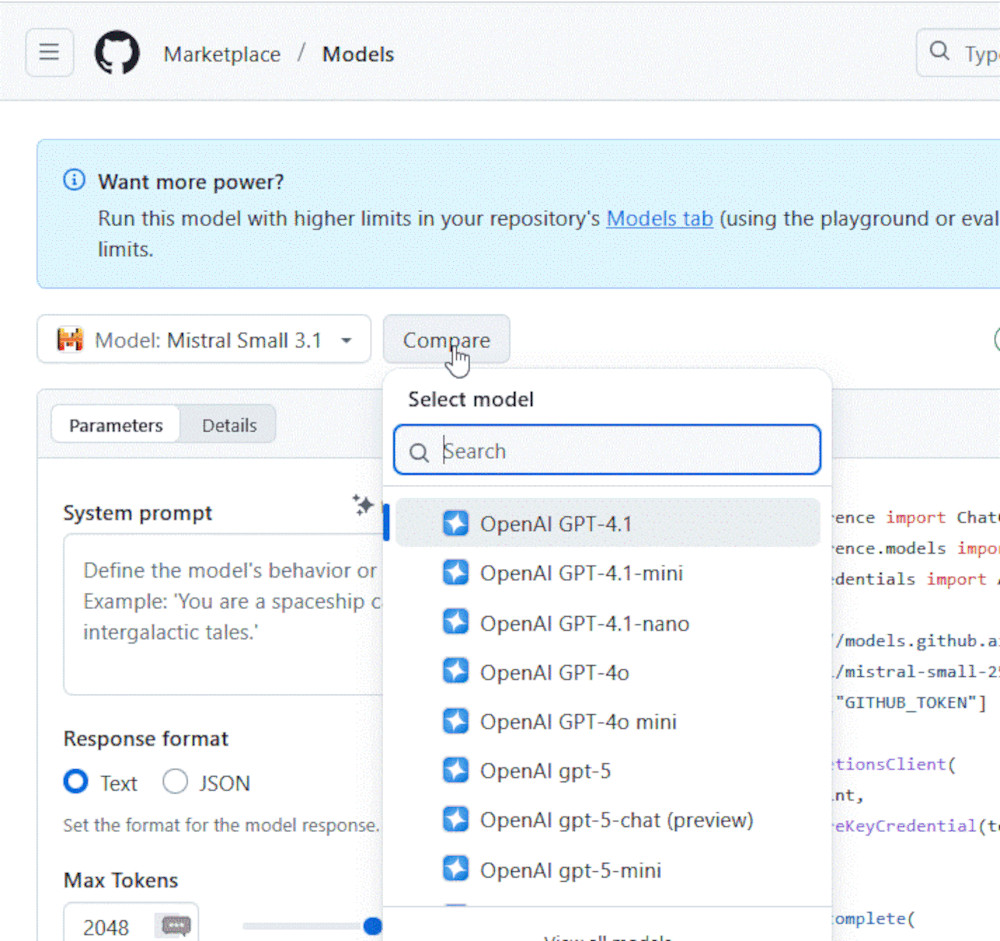
Weiteres Modell zum Vergleich wählen
Im Suchfeld geben Sie den Namen des Modells an, mit dem Sie das aktuell gewählte vergleichen möchten. Dann wird der Bildschirm zweigeteilt, und Sie sehen beide Modelle nebeneinander. Wenn Sie unten einen Prompt eingeben, wird er nun an beide Modelle gesendet, und Sie können die Ergebnisse analysieren.
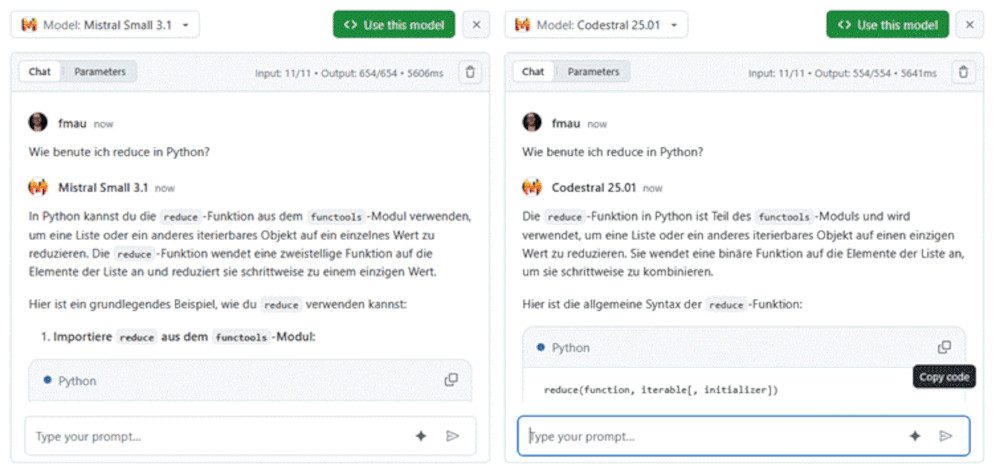
Ergebnisse vergleichen
Standardmäßig werden dieselben Prompts an beide Modelle gesendet, auch die Parameter sind identisch. Wenn Sie das nicht möchten und für jedes Modell andere Parameter definieren wollen, klicken Sie auf Parameters. Ganz oben sehen Sie die Checkbox Sync chat input and parameters, die standardmäßig aktiviert ist.
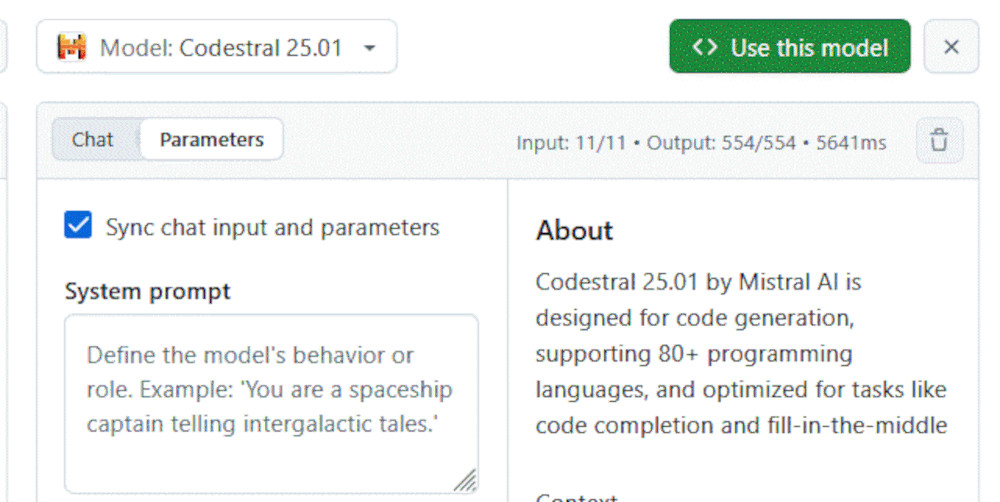
Sollen Prompt und Parameter bei beiden Modellen gleich sein?
Bei Bedarf deaktivieren Sie diese Checkbox, dann lassen sich die Modelle einzeln konfigurieren.
Auf die gerade gezeigte Art können Sie übrigens auch ein Modell mit sich selbst und mit verschiedenen Parametern vergleichen.
Use this model
Sehr prominent steht in den Fenstern der Button Use this model. Ein Klick darauf zeigt, wie man das Modell praktisch nutzt, und liefert dafür eine detaillierte Anweisung. Die Sprache und das gewünschte SDK wählen Sie im linken Bereich.
Am Anfang ist es wichtig, die Authentifizierung zu konfigurieren. Dafür können Sie ein Personal Access Token in GitHub erstellen, oder es geht über Azure AI „pay as you go“. Sie erhalten weitere Informationen, wie Sie das Token als Environment-Variable exportieren, dann die benötigten Bibliotheken installieren, Beispielcode ausführen und wie Sie von der kostenlosen Nutzung zu einer bezahlten wechseln.
Ratenbegrenzung und Kosten
Bei den Details der einzelnen Modelle wird auch die Free-Rate-Limit Stufe angegeben. In der kostenlosen Version gibt es Beschränkungen für die Nutzung. Die konkreten Obergrenzen hängen zuerst einmal vom gewählten Modell ab. Dafür werden die Modelle in unterschiedliche Ebenen eingeordnet. Zusätzlich spielt es eine Rolle, was für ein Copilot-Nutzer Sie sind. Die genauen Bedingungen sind unter Ratenbegrenzungen aufgeführt.
Angegeben ist jeweils die Anzahl an möglichen Anforderungen pro Minute, pro Tag, sowie die Tokens pro Anforderung und wie viele gleichzeitige Anforderungen möglich sind. Ein Beispiel: Bei der Ebene Niedrig/Low kann man beim Copilot Free-Konto 15 Anforderungen pro Minute senden, allerdings nicht mehr als 150 pro Tag; die Anzahl an Tokens ist auf 8.000 für den Input und 4.000 für den Output beschränkt und es können nicht mehr als fünf Anforderungen gleichzeitig gesendet werden.
Für erste Experimente ist das auf jeden Fall eine gute Basis, wenn Sie mehr benötigen, können Sie zur kostenpflichtigen Version wechseln. Informationen zu der Abrechnung lesen Sie unter Abrechnung für GitHub-Modelle.
GitHub Models – Fazit
Der Einstieg in GitHub Models gelingt leicht – und macht die Hürde zum Ausprobieren und Experimentieren von Modellen niedriger.
Sehr praktisch ist besonders die Vergleichsfunktion, mit der man verschiedene Modelle gegenüberstellen und mit den Parametern experimentieren kann. Oder man vergleicht ein Modell mit sich selbst bei Verwendung unterschiedlicher Parameter.
Außerdem ist es praktisch, dass sich so viele geballte Informationen über verschiedene Sprachmodelle an einer Stelle finden. Damit helfen die GitHub Models nicht nur beim Vergleich und Experimentieren, sondern auch bei der Beantwortung der beiden Kernfragen: ob und wie sich KI sinnvoll einsetzen lässt – und welches Modell mit welchen Einstellungen sich dafür am besten eignet.
Titelmotiv: Photo by Rubaitul Azad on Unsplash

- GitHub Models: KI-Modelle direkt im Browser testen - 5. Februar 2026
- Tailwind CSS bei WordPress einsetzen – so geht’s! - 16. Juli 2025
- Eine Einführung in Tailwind CSS – warum ist das Utility-First-Framework so populär? - 7. Mai 2025
