Immer mehr Anwendungsgebiete und Anwendungsfälle werden von den “persönlichen virtuellen Assistenten, die sprechen können” (meine Bezeichnung für digitale Sprachassistenten) wie Amazon Alexa, Google Assistant oder Samsung Bixby erschlossen. Diese faszinierende Entwicklung ist längst nicht beendet und steckt noch immer in den Anfangstagen.
Die Spracherkennung der Systeme nähert sich einem hohen Grad an Qualität, und fast täglich können diese Systeme mehr. Trotzdem kommt der Nutzer aktuell über recht einfache Anwendungsfälle wie „Fragen und Antworten“ oder der Sprachsteuerung in der Regel nicht hinaus.
Der Tag, an dem der Nutzer mit den Maschinen so natürlich sprechen kann wie mit anderen Menschen, ist in jedem Fall noch Jahre entfernt. Kontexterkennung und künstliche Intelligenz sind halt wissenschaftlich komplexe und umfangreiche Felder, die noch viel Entwicklung brauchen.
Die rasant steigende Nutzung der Stimme in der Kommunikation mit der Maschine bringt menschlichere Verarbeitungsweisen mit sich
Die Absichten digitaler Sprachassistenten
Die gesprochene Sprache, die Stimme und das Gehör bringen andere Eigenschaften, Wirkungen und Notwendigkeiten mit, als die Tastatur, das Auge und der Bildschirm es bisher gefordert haben. In einer „Smart Voice“ Entwicklung gilt es, das als allererstes zu verstehen, um sie dann als Kern jeder weiteren Entwicklung für digitale Sprachassistenten heranzuziehen zu können. Dies konzentriert sich vor allem auf die Art und Weise, wie Menschen sprechen, womit nicht nur gemeint ist, welche Worte sie in welcher Sprache sprechen, sondern vor allem, was sie mit diesen Worten „beabsichtigen“. Denn Absichten (= Intents) sind das Wesen des menschlichen Denkens, Handelns und Sprechens. Die digitalen Sprachassistenzsysteme sind von Grund auf genau dafür ausgelegt, auch wenn sie diese Interpretation von Absichten bisher noch nicht oder nur rudimentär leisten können.
Entsprechend ist dieser auf Absichten basierte Entwicklungsansatz auch noch nicht bei den Entwicklern und Designern angekommen. Wie auch? Sie hatten bisher erst einmal die Aufgabe, die Grundlagen zu stemmen und die noch sehr volatilen Systeme steuern zu lernen. Doch so langsam dringt die Intent-basierte Denkweise auch hier in die Köpfe. Wer über die letzten Jahre die Entwicklungen besonders von Googles Suchmaschine verfolgt hat, wird schnell feststellen, dass die meisten Entwicklungen ganz klar in Richtung „Sprechbarkeit“, auf der Basis menschlicher Absichten und virtueller Assistenz geht: „Get things done!“ (Sundar Pinchai – Google IO 2019).
Der Mensch will sich in jeder Sekunde seines Lebens ausgleichen. Um dies zu tun, formt er Absichten, die er dann (meistens) entweder umsetzt oder eben mitteilt. Insofern diese Mitteilung nicht von einem Menschen empfangen und interpretiert wird, dann wohl aber schon jetzt immer mehr vom persönlichen virtuellen Assistenten, der sprechen kann — dem digitalen Sprachassistenten.
Bei Smart Voice und digitalen Sprachassistenten geht es im Grunde nicht um die Ausgabe von Informationen per Stimme, sondern um die dahinterliegenden Informationen, die die Stimme beinhaltet – situative Emotionen und Absichten!
Der digitale Sprachassistent erfüllt die Absicht seines Nutzers, oder bietet ihm zumindest eine mögliche Erfüllung an. Stets in einer Form, die „Voice First“ gestaltet ist und durchaus auch multimodal sein kann, wie zum Beispiel mit einem Bildschirm.
Nein, das ist keine Zukunftsmusik. Auch wenn die aktuell gut zu nutzenden Anwendungsfälle noch recht einfach sind, so sind sie bereits der Weg zum persönlichen virtuellen Assistenten, der mit dem Menschen in Dialogen spricht und Dinge für ihn erledigt.
Durch die große „situative Emotionalität“ des Kommunikationskanals Stimme und Gehör müssen Entwickler die „Persona“ (Zielnutzer) wie folgt definieren….
- Wer: z.B.: Schlumpf, Feuerwehrmann, Kind, Ente…
- Wo: z.B.: Badezimmer, Arbeit, Zuhause, Shoppingcenter…
- Wann: z.B.: Nachts, beim Einkaufen, beim Sex, beim Fernsehen…
- Mentalität: z.B.: Wütend, Verliebt, Glücklich, Enttäuscht…
… und dies mit der möglichen „situativen Absicht des Nutzers“ in Einklang bringen.

Was würde ein Mensch hier einsetzen, wenn er frisch verliebt oder frisch getrennt wäre?
Viele werden sich nun die Frage stellen, was dies alles mit dem Internet zu tun hat. Nun, digitale Sprachassistenten sind eine Brücke zum Internet, genauso wie Smartphones oder Notebooks, jedoch auch oft ohne Bildschirm. Oder mit Bildschirm, aber eben mit einer Sprach-Ein- und Ausgabe (Multimodal). Da die Nutzung digitaler Sprachassistenten rapide zunimmt, müssen die Inhalte und Prozesse im Internet entsprechend für diesen Kommunikationskanal gestaltet sein, weil sie sonst beim Nutzer versagen und damit am Markt verlieren. Schon heute…
Das Rüstzeug für Smart Voice Entwicklungen
Der digitale Sprachassistent holt sich seine Informationen zum größten Teil aus dem eigenen System, aber auch aus externen Quellen wie z.B. einer Suchmaschine oder Internetseiten. Um also über den Kanal der digitalen Sprachassistenten sichtbar zu sein, braucht es eine Smart Voice/Voice First Entwicklung über alle Medien hinweg, damit der digitale Sprachassistent Informationen vorfindet, die für ihn stets sprechbar sind, egal wo die Quelle dieser Informationen auch war. Des Weiteren verändert sich durch die rasant zunehmende Nutzung der Medien mit gesprochener Sprache auch der Anspruch an sämtliche Inhalte und Prozesse generell, so dass alles, was bisher für den Bildschirm gestaltet war, nun den Regeln von Gehör und Stimme folgen muss, um nah am Nutzer zu bleiben.
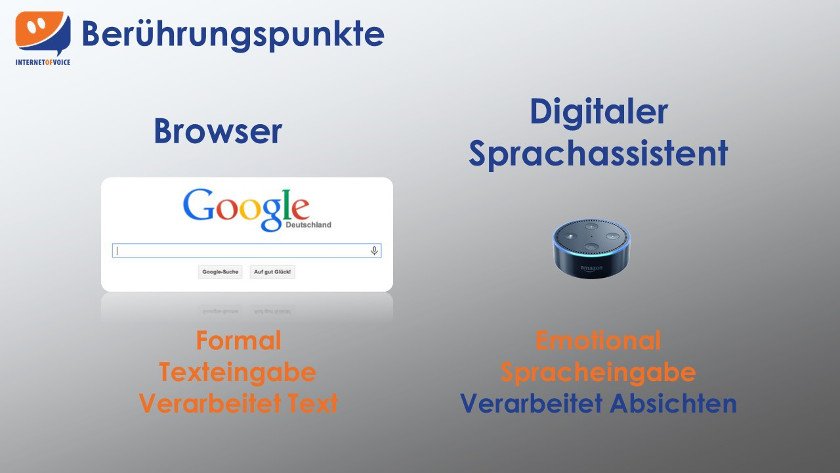
Sprechbarkeit – Sprache vs. Stimme vs. Gehör
Der Linguist des Vertrauens oder die Audiobranche ist dem Wissen, welches nötig ist, um Sprechbarkeit herzustellen, am nächsten. Inhalte und Prozesse müssen für die Ausgabe von Informationen per Stimme und dessen Empfang per Gehör nach den Regeln von Gehör und Stimme angepasst werden. Diese Regeln sind wesentlich andere, als die Regeln der letzten Dekaden, die für die Gestaltung des Bildschirms erlernt und genutzt wurden.
Da niemand schreibt wie er spricht, müssen auch insbesondere Texte sprechbar gemacht werden. Es reicht bei Weitem nicht, die Texte der vorhandenen Internetseite in den digitalen Sprachassistenten zu kopieren. So sollten sämtliche gesprochene Worte und Sätze nie mehr als maximal acht Sekunden Zeit des Hörers in Anspruch nehmen, um das Ohr des Zuhörers nicht zu ermüden. „Informationshäppchen“ und Dialoge sind die Werkzeuge, um ohrfreundlich beim Nutzer anzukommen. Natürlich müssen Sonderzeichen und sonstige graphische Informationen entweder gänzlich weggelassen oder eben beschreibend versprachlicht werden.
Audioinformationen wie z.B. ein Musikstück lassen sich zwar auch per Stimme beschreiben, jedoch macht die tonale Ausgabe natürlich mehr Sinn, als sie vom Sprachassistenten beschreiben zu lassen. Aber es werden auch versprachlichte beschreibende Daten (Meta-Daten) der Audioinformation benötigt, damit der Nutzer z.B. auch danach fragen, und der Sprachassistent diese Information dem Nutzer ausliefern kann.
Gleiches gilt für Bilder und Videos, wobei diese je nach Anwendungsfall auch auf einem Bildschirm angezeigt werden müssen.
Da die Technik noch nicht in der Lage ist, Gerüche direkt an den Nutzer auszuliefern (was wohl auch besser so ist…), ist klar, dass diese Informationen nur beschreibend abgebildet werden müssen, um sie sprechbar zu machen. Bei Emotionen ist das anders. Die Stimme kann durch entsprechende Anpassung der Stimmlage auch nun erstmalig Emotionen an den Nutzer ausgeben, und genau dies ist das Novum der digitalen Sprachassistenten.
Der Mensch vertraut dem Gehörten mehr als dem Gesehenen. Aus diesem Grund ist auch die Marktveränderung vom Bildschirm zum Sprachassistenten eine Veränderung des Vertrauens zur Maschine, ein „Shift of Trust“. Wogegen z.B. die Marktveränderung vom Desktop-Bildschirm zum Smartphone hin eine reine Verhaltensänderung war.
Sprechbarkeit ist zeitgleich auch Hörbarkeit. Das Gehör erwartet eine langsame und serielle Information, die möglichst emotional und vertrauensvoll „auf den Punkt“ gebracht ist. Dieser „Punkt der Erfüllung“ lässt sich am einfachsten anhand einer Liste erklären, die man vorgelesen bekommt. Je länger die Liste ist, umso schwieriger ist es für den Menschen, die einzelnen Listenpunkte im Kopf zu behalten. Im Grunde ist dieser Punkt der Erfüllung für das Ohr gut mit der „Position Null“ einer Suchmaschine vergleichbar.
Sprache – Mehr als Formalität > Emotion und Absichten
Wer mit der Sprache umgehen will, muss sie natürlich auch verstehen. Die Eigenschaften und Wirkungen von Sprache sind dabei auf den ersten Blick nicht wirklich offensichtlich, weil in der Schule nur die Formalität von Sprache gelehrt wird: Rechtschreibung und Grammatik.
Dabei ist Sprache sehr mächtig. Dessen bewusst sind sich Philosophen, Linguisten, Journalisten und alle, die aus der Audio-Branche kommen, genau wie Politiker oder Menschen der Bühne.
Die grundsätzlichste Eigenschaft von „Sprache per Stimme“ ist ihre große Emotionalität und das große Vertrauen, welches der Mensch der Stimme entgegenbringt. Entsprechend dem für ein geplantes Smart Voice Projekt gesetztem Ziel, sollte die Stimme des Sprachassistenten in einer Art gestaltet sein, die dem Ziel entspricht. Obwohl es so elementar wichtig ist, ist dies ist bei aktuellen Entwicklungen momentan so gut wie nicht der Fall. Der Grund dafür liegt in der noch jungen Methodik zur Entwicklung von Voice User Interfaces (VUI). Doch besonders das Marketing hat dies bereits erkannt und diskutiert eifrig über z.B. „der Marke angepasste Stimmen“, sogenannte Voice Brands.

Voice Brands sind Teil einer Smart Voice Strategie, aber nicht die Strategie selbst!
Um sich in jeder Sekunde seines Lebens auszugleichen, denkt, handelt und „spricht“ der Mensch in Absichten (Intents), und genau um diese geht es im Kern bei digitalen Sprachassistenten.
Es geht darum, dass der „persönliche virtuelle Assistent, der sprechen kann“, die Absichten des Nutzers erledigt, oder zumindest ihn hinführt.
Für diesen Zweck sind die aktuellen Systeme wie Alexa oder Google Assistant gestaltet, auch wenn sie den nötigen Leistungsumfang für diese komplexe Aufgabe noch nicht erreicht haben. Wenn der digitale Sprachassistent also Informationen zusammenträgt, die er seinem Nutzer liefern will, so müssen diese ohrgerecht aufbereitet sein, egal aus welcher Quelle. Genau hier kommen dann auch solche Themen ins Spiel wie das schon oft belesene „Voice Search“ .
Voice Search
Das Verquere an Voice Search ist, dass es so etwas wie eine Voice Search Optimierung für Internetseiten eigentlich noch gar nicht gibt. Die „Stimme“ wird von den Suchmaschinen aktuell noch gar nicht ausgewertet, um eine Suche auszuführen. Das was ausgewertet wird, ist das Gleiche wie zuvor, auch wenn die Eingaben über das Mikrofon eher ganze Sätze sind, als nur Schlagwörter per Tastatur. Die aktuell in vielen Artikeln und Vorträgen empfohlenen Maßnahmen zur Voice Search Optimierung sind gänzlich normale Optimierungen für den Bildschirm, wie sie als Hausaufgabe eh gemacht werden sollten. Wer jedoch seine Informationen auch über den situativ-emotionalen Kanal der digitalen Sprachassistenten an die Nutzer adressieren möchte, muss seine Informationen so oder so, wie bereits oben erwähnt, sprechbar machen und zwar zentriert auf die mögliche „Absicht“ eines Nutzers.
Wenn es also so etwas wie eine „Voice Search“ und damit auch „Voice Search Optimierung“ geben soll, dann muss diese Suche eigentlich auf den „Absichten“ (Intents) basieren und nicht nur einfach auf Texterkennung.
Google hat in Richtung Sprache schon viele kleine Schritte unternommen, um den Regeln der Sprache zu folgen, auch wenn die Stimme selbst noch keinen Einfluss auf das Ranking von Informationen hat. Amazon stellt in seinem Alexa-System die Rankingfaktoren für die Intents der Alexa-Skills sogar öffentlich zu Schau (Hyp-Rank), jedoch findet die Emotion der Stimme auch hier noch keinen Niederschlag.
Die Stimme kann Handlungsdruck erzeugen, genauso wie sie Emotionen und Vertrauen ausdrücken und erzeugen kann. Diese Gestaltungselemente sind es, die digitale Sprachassistenten als Medium so nah an den Menschen bringen, wie noch nie zuvor ein Medium, und die sie damit extrem effizient machen.
Voice First Gestalten – Voice User Interfaces (VUI)
Aus Mobile First wird Voice First, denn der Mensch nutzt immer mehr die Stimme in der Kommunikation mit Maschinen. Dies bedeutet, dass sämtliche Gestaltungen erstmal nur auf Basis von Stimme und Gehör geplant werden, bis ein Sattelpunkt erreicht wird (Punkt der Multimodalität), an dem die Information nicht mehr gut per Stimme/Gehör transportierbar wird. Ab diesem Sattelpunkt müssen dann weitere Medien, wie z.B. ein Bildschirm, hinzugenommen werden, um die Information smart abzubilden.
Eine Gestaltung von digitalen Sprachassistenten/Smart Voice bedeutet nicht, dass man sklavisch keinen Bildschirm oder andere Medien nutzen darf, sondern dass alle zu nutzenden Medien per Stimme bedienbar werden.
Die Reise eines Nutzers durch die Inhalte und Prozesse einer Anwendung (Customer Experience), wird durch Smart Voice fundamental erweitert. Die Konzentration auf die situative Absicht und die Emotion des Nutzers ermöglicht dabei eine hochwertige Kanalisierung der Nutzer, hin zum bereits erwähnten „Punkt der Erfüllung“. Für Designer, Programmierer und Entwickler bedeutet dies vor allem, dass alle Medien in dieser Art ausgelegt sein müssen, also auch Apps, Internetseiten und sonstige Nutzeroberflächen.
Für unsere Kinder werden Geräte, die nicht sprechen können, „kaputt“ sein!
Es gibt für Entwickler inzwischen eine ganze Menge an Informationen zur Gestaltung von Voice User Interfaces, auch wenn diese Informationen und Nachschlagewerke natürlich noch sehr volatil sind und die noch nötige Entwicklung hin zum Kern der digitalen Sprachassistenten; dem Intent / der Absicht noch nicht vollzogen haben. Die Dokumentationen der Provider (Apple Siri, Samsung Bixby, Microsoft Cortana, Google Assistant, Amazon Alexa) sind die erste Anlaufstelle. Inzwischen gibt es auch zahlreiche YouTube Videos, Internetseiten und Foren (wie z.B. die Facebook Gruppe deutscher Alexa Entwickler), die diese Themen umfassend behandeln.
https://www.youtube.com/watch?v=o7V_enpYuPE&list=PLDfLboptC7T-ozga-1jIzC7I6j4XwrLw6
Neben zahlreichen Entwicklern, die sich in digitalen Sprachassistenten ausprobieren und vielerlei Skills und Actions hervorbringen, sind auch bereits ein paar Ressourcen entstanden, die es dem Entwickler einfacher machen sollen, gute Smart Voice bzw. Voice First Entwicklungen anstoßen zu können. Dazu gehören neben den Funktions- und Informationsbibliotheken der Voice-Service-Provider (z.B. Google Actions und Alexa Voice Service) insbesondere Gestaltungshilfen und Frameworks wie z.B. BotTalk, die vor allem dabei helfen, sich nicht unbedingt nur auf eine bestimmte Programmiersprache festzulegen, sondern fast jede Programmiersprache nutzen zu können.
Auch wenn jedem Entwickler, der es mit Sprachassistenten ernst meint, der Satz „Entwickeln ohne Programmierung!“ die Haare zu Berge stehen lässt, so haben auch derartige Werkzeuge ihre Berechtigung und erlauben es weniger in Programmierung versierten Menschen einfache Anwendungsfälle für digitale Sprachassistenten umzusetzen.
Außerdem gibt es schon länger verschiedene Veranstaltungen, auf denen die Gestaltung von digitalen Sprachassistenten und VUIs vermittelt wird. Diese sind in der Regel in allen größeren Städten in unregelmäßigen Abständen zu finden und erfreuen sich großen Zulaufs.
Digitale Sprachassistenten auf allen Kanälen
Smart Voice, die Nutzung der Stimme und digitale Sprachassistenten, die in allen möglichen Geräten eingebaut sind, sind kein Zukunftsthema, sondern schon seit ein paar Jahren Realität. Dieser vom Menschen stark geforderte “Voice First” Entwicklung müssen alle digitalen Gestalter über alle Kanäle Folge leisten, um am Nutzer zu bleiben. Aufgrund der komplexen wissenschaftlichen Basis für Sprache und künstliche Intelligenz ist diese Entwicklung eine eher langsame, aber stetige und damit keine herbei gehypte Revolution.
Smart Voice zu entwickeln heißt nicht, eine Sprachanwendung zu programmieren, sondern sämtliche Inhalte und Prozesse über alle Medien und Kanäle hinweg auf die Regeln der Stimme und des Gehörs anzupassen. Das bedeutet auch, die Nutzung des Bildschirms weiterhin stets im Blick zu haben. Voice First heißt nicht zwingend Voice only. Die emotionale Absicht des Nutzers (User Intent) ist dabei immer nicht nur das Qualitätsmerkmal einer guten Entwicklung, sondern auch der Ankerpunkt für jegliche Strategie. Programmiert wird erst ganz am Schluss, und das sollte nicht mehr als 20 Prozent der Mittel für ein gesamtes Smart Voice Projekt darstellen.
Sie möchten, dass digitale Sprachassistenten besser werden? Dann nehmen Sie an dieser Umfrage teil. Die Ergebnisse werden allen Interessierten kostenlos zur Verfügung gestellt.

Email: r.mendez@internet-of-voice.de
https://intent-marketing.de
https://vui.dev
